Более сложные модели IRT: 2PL
Рубрика #приглашенный_эксперт #психометрика #IRT #R
Публикую вторую часть поста (см. первую часть) в новой рубрике канала #приглашенный_эксперт. Во второй части Денис Федерякин рассматривает более сложные модели IRT.
Двухпараметрическая логистическая модель Алана Бирнбаума (2PL) отличается от модели Раша (1PL), про которую мы говорили в прошлый раз, добавлением еще одного параметра для каждого задания – дискриминативности этого задания. Дискриминативность – это "чувствительность" задания к изменению в латентной характеристике. Этот параметр называется так, потому что психометрики хотят, чтобы задания дискриминировали респондентов по уровню способности: нужно, чтобы слабые респонденты задания решали неправильно, а сильные – правильно. Психометрики хотят иметь задания с высокой дискриминативностью в тесте, потому что, когда задания сильно чувствительны к изменению в способности, надежность измерения повышается.
Если сравнить формулы моделей 1PL и 2PL, становится понятно, что 1PL – это частный случай 2PL, в котором все задания имеют одинаковую дискриминативность (что в практике, конечно же, никогда не происходит). Однако разница между этими моделями в интерпретации гораздо более глубокая, чем эти математические отношения между моделями. Тот факт, что все задания в 1PL имеют одинаковую дискриминативность приводит к тому, что вероятность правильно решить более легкое задание на всем континууме способности (т.е., для всех респондентов) более высокая. Это значит, что иерархия заданий по трудности всегда едина в 1PL. Соответственно, это позволяет строить т.н. "карту конструкта" – от того, какие задания являются самыми легкими, до того, какие являются самыми трудными.
theta = seq(-3,3, .1)
b1 = -0.5
a1 = 1.1
b2 = 0
a2 = 1.7
P1 = 1 / (1 + exp(-1*(a1*(theta - b1))))
P2 = 1 / (1 + exp(-1*(a2*(theta - b2))))
plot(theta, P1, type = "l", ylim = c(0,1), col="red",
main = "Два задания в 2PL модели",
xlab = "Способность (латентный параметр) в логитах",
ylab = "Вероятность правильного ответа")
par(new=TRUE)
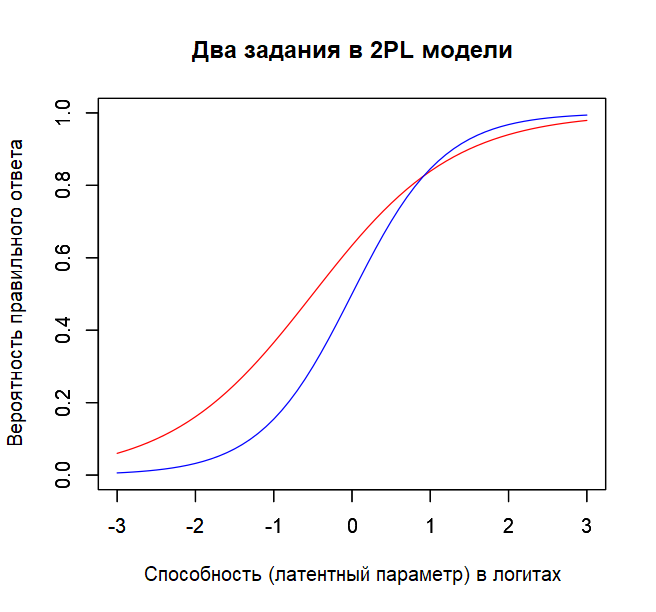
plot(theta, P2, type = "l", ylim = c(0,1), col="blue", xlab = "", ylab = "")Теперь, посмотрим на рисунок двух характеристических кривых заданий в 2PL (характеристическая кривая задания – это функция, отражающая вероятность решить данное задание на разных уровнях способности). Из-за то, что задания в рамках 2PL могут отличаться (т.е., практически всегда отличаются) по дискриминативности, их характеристические кривые пересекаются. Это приводит к тому, что до их точки пересечения красное задание легче, чем синее (вероятность его решить выше), а после точки их пересечения – все наоборот. Это приводит к тому, иерархию заданий по трудности в 2PL выстроить невозможно. Даже несмотря на то, что параметр «трудности» все равно есть в 2PL модели, ранжирование задание по нему не имеет смысла, т.к. после каждого пересечения двух характеристических кривых, происходит изменение порядка заданий.
Конечно же, это математическое различие сказывается и на согласии данных с моделью. Модель 2PL гораздо менее придирчива, чем 1PL к качеству заданий: больше параметров = модель гибче = больше заданий находятся в согласии с ней. Поэтому, когда тест разрабатывается, например, под 1PL модель, требуется гораздо больший запас заданий до апробации, потому что очень много из них будут признаны несогласующимися с ней и выкинуты из теста.
Такая интерпретационная тонкость определяет, как эти модели применяются в психометрической практике. Так, 1PL модели популярны при моделировании образовательных тестов (и иногда – тестов достижений). Это обосновано интерпретационно, потому что, например, школьник не может решать квадратные уравнения, пока он не знает, как решать линейные. В этом смысле, выстраивание карты конструкта в терминах заданий оправдано, потому что сам по себе предмет измерения имеет упорядоченность в терминах поведенческих проявлений. Однако 2PL чаще применяется при психологических измерениях. В них гораздо труднее выстроить единую карту конструкта, и считать, что, например, в тесте на экстраверсию всем респондентам труднее заговорить с незнакомым человеком на улице, чем на вечеринке у друзей (или наоборот). Таким образом, разработка теста для 1PL больше похожа на стратегическое размещение зданий на карте конструкта – от простых к сложным. Модель 2PL же извлекает из данных некоторую способность, которая просто является чем-то наиболее общим из всех заданий. Однако в самом простом случае все модели IRT все еще являются одномерными – они допускают, что ответы на все заложенные в них задания зависят от одной способности.
Напоминаю, что сотрудники Института образования НИУ ВШЭ подготовили цикл программ дополнительного профессионального образования, который поможет глубже разобраться в психометрике всем желающим. Эти программы научат не только интерпретации и понимаю структуры психометрических моделей, но и их применению на языке программирования R (см. код выше в тексте второй части).
Обучение начинается 30 мая 2022 года (см. более подробную информацию об этом цикле программ повышения квалификации).