Коэффициент корреляции для категориальных переменных

Было бы здорово, если бы существовал способ создать корреляционную матрицу для категориальных переменных как для числовых, где все значения находятся в одном масштабе. Теперь и это возможно. Читайте дальше — расскажем, как это можно сделать.
- Введение
- Пример бинарной классификации
- Доказательство
- Снова пример бинарной классификации
- Частные случаи
- p-value
- Пример многоклассовой классификации
- Корреляционная матрица
- Заключение
Введение
Наиболее распространенная причина, по которой необходимо знать корреляцию между переменными, заключается в разработке предиктивных моделей. Чем выше корреляция факторной переменной и целевой, тем лучше предсказательная способность модели. Проверка корреляций между факторными переменными необходима для исключения из модели мультиколлинеарности, которая, в свою очередь, ухудшает качество модели.
Для числовых переменных мы можем создать таблицу (корреляционную матрицу), чтобы увидеть корреляции всех факторных переменных с целевой переменной и между всеми факторными переменными между собой. Сравнения просты, поскольку все корреляции находятся на одной шкале (от -1 до 1). Но с категориальными переменными дело обстоит иначе.
Для категориальных переменных корреляционную матрицу использовать нелегко и не всегда имеет смысл, поскольку вычисленные значения могут быть несравнимы друг с другом. Каждое значение корреляции имеет свое критическое значение, с которым его необходимо сравнивать, и оно меняется в зависимости от степеней свободы каждой пары переменных (и выбранного доверительного уровня). Например, у нас может быть три корреляции с целевой переменной — 20, 30 и 40. Переменные с корреляцией 20 и 30 могут иметь пять степеней свободы и быть выше своего критического значения 15. Но переменная с корреляцией 40 может быть ниже своего критического значения 45 и вообще не быть связана с целевой.
Было бы здорово, если бы существовал способ создать корреляционную матрицу, где все значения находятся в одном масштабе, как это можно сделать для числовых переменных. И теперь это возможно.
Пример бинарной классификации
Представим, что у нас есть бинарная целевая переменная со значениями A и B и бинарная факторная переменная со значениями C и D. Если при значении факторной переменной C зависимая переменная будет принимать значение A, а при значении факторной переменной D зависимая будет принимать значение B, то у нас будет идеальный предиктор. У нас была бы самая эффективная модель, если бы это был единственный признак нашей модели. Метрики будут идеальными, а прогнозный коэффициент был бы равен 1. А если значение каждой факторной переменной имеет соотношение 50/50 между A и B, то мы имеем наименее полезный предиктор. Если бы это был единственный входной параметр нашей модели, то мы получили бы модель с наихудшими показателями. Прогнозный коээфициент был бы равен 0. То же самое относится и к взаимосвязям между факторными переменными. Если одна из них соответствует другой в 100% случаев, то мы модель по сути оперирует одной и той же информацией, и необходимо провести проверку взаимосвязи между ними.
Давайте разбираться, почему так. Распределение бинарной переменной 50/50 будет равномерным. Мы спрашиваем: насколько распределение целевой переменной соответствует равномерному распределению для каждого значения факторной переменной? Если они полностью совпадают, каждое значение целевой переменной встречается одинаковое количество раз, то это значение факторной переменной наименее информативно для модели. Если это справедливо для всех значений, то прогнозный коэффициент будет равен 0. Наиболее информативна для модели будет ситуации, когда распределение максимально далеко от равномерного (в крайней ситуации, когда все значения факторной переменной приводят к одному значению целевой). Если это так для всех значений факторной переменной, то прогнозный коэффициент будет равен 1. Тот же принцип обобщается на категориальные переменные с любым количеством значений.
Давайте оценим это количественно. Для любого набора данных с двумя категориальными переменными мы создаем таблицу сопряжённости, где каждая ячейка представляет собой количество строк с данной комбинацией фактора/целевой переменной. Например:

Мы просуммируем все строки, чтобы получить суммарное количество каждого значения факторной переменной.

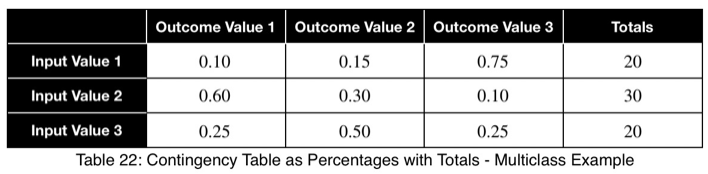
Рассчитаем процент появления каждого значения целевой переменной для каждого значения факторной переменной путем деления на итоговые значения в каждой строке. Получим следующие доли:

Рассчитаем отклонение от ожидаемого значения равномерного распределения, 0.5 для двух возможных значений, и нормализуем результаты. Сделаем расчёт по формуле стандартного отклонения:
- n — это количество уникальных значений целевой переменной во всём наборе данных. Предполагаем, что все они одинаково вероятны;
- 1/n — это вероятность получения любого одного значения целевой переменной, ожидаемое значение равномерного распределения;
- xⱼ — это процент появления каждого из j значений целевой переменной для каждого значения факторной переменной. Для каждого из i значений факторной мы вычисляем следующее:
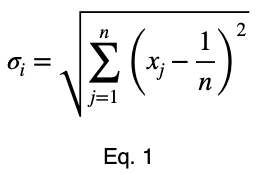

Затем мы нормализуем эти значения по максимальному значению, которое может принять уравнение 1.
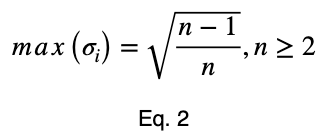
Доказательство
Для доказательства воспользуемся математической индукцией.
Математическая индукция гласит, что для всех целых чисел n и k, если мы можем доказать, что что-то верно для n = k и n = k + 1, то это верно для всех n ≥ k. Мы покажем, что это верно для n = 2 и n = 3. Тогда по математической индукции это будет верно для всех n ≥ 2.
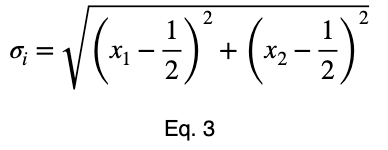
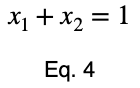
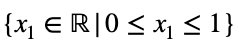
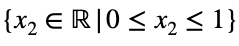
Мы можем решить уравнение 3 для x₁ и подставить его, чтобы сделать уравнение 3 функцией с одной переменной.
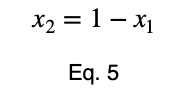
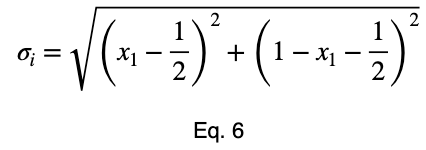
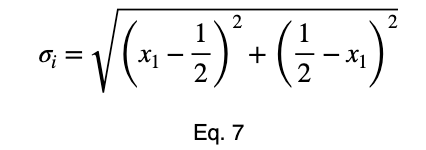
Возьмем производную, приравняем её к нулю и найдем критические точки.
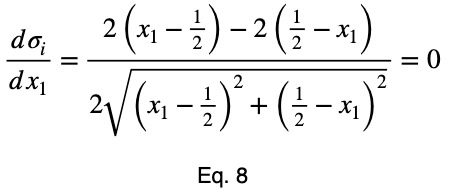
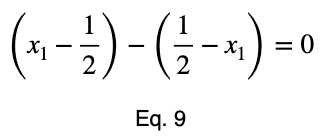
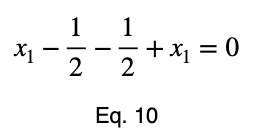
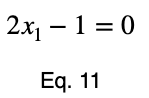
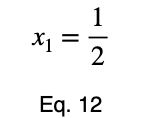
Используя уравнение 5, находим критическое значение x₂, соответствующее этому значению x₁.
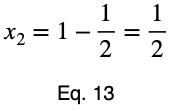
Теперь создадим таблицу значений функции в критической точке и конечных точках, чтобы определить максимальное значение.

Максимальное значение появляется при (x₁, x₂) = (0, 1) и (x₁, x₂) = (1, 0), которые оба оцениваются как:
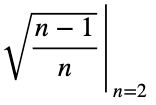
Для n = 3 воспользуемся методом множителей Лагранжа.
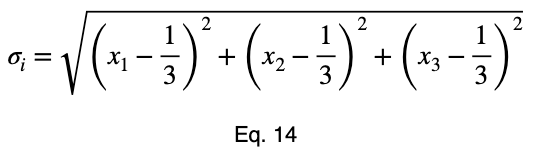
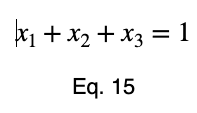
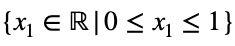
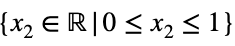
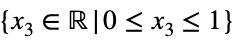
Мы преобразуем наше уравнение в функцию, приведя все члены к одной стороне уравнения.
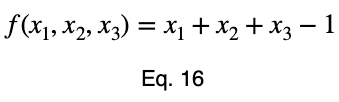
Возьмём производную 𝜎ᵢ относительно x₁ и установим её равной производной f(x₁, x₂, x₃) относительно x₁, умноженной на множитель Лагранжа λ.
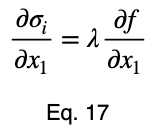
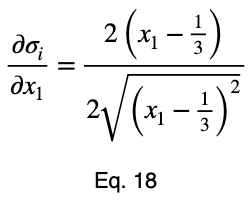
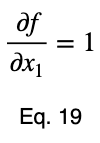
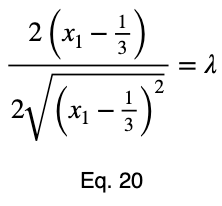
Обычно мы повторяем эту процедуру для x₁ и x₂, решаем для каждого из них по λ, подставляем их в уравнение ограничений и используем эти четыре уравнения для решения четырех неизвестных, получая критические точки. Но при упрощении уравнения 20 наши члены λ отменяются, и мы решаем x₁ напрямую.
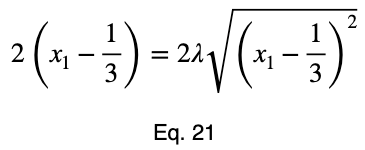
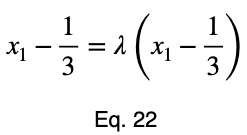
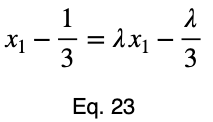
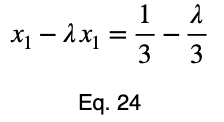
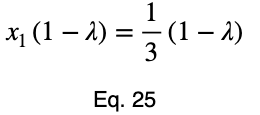
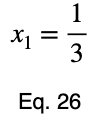
Уравнения для решения x₂ и x₃ такие же, как и для x₁. Это дает нам критическую точку.
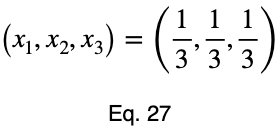
Теперь мы создадим таблицу значений, оценивая нашу функцию в данной точке и её конечных точках.

Наше максимальное значение — это квадратный корень из 2/3, который равен
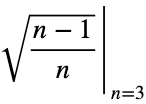
По математической индукции, максимальное значение:
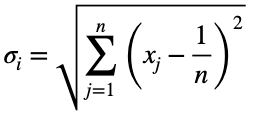
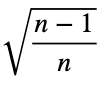
для всех целых n ≥ 2 и для всех действительных чисел xⱼ таких, что для каждого xⱼ
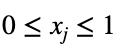
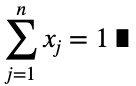
Для n = 1 мы имеем простой случай, когда существует только одно значение целевой переменной.
Снова пример бинарной классификации
Теперь разделим на квадратный корень из 1/2, чтобы получить нормализованную вариацию, ψᵢ .
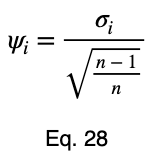

Возьмём среднее значение этих величин, чтобы получить прогнозный коэффициент ω. Пусть m — это количество уникальных значений факторной переменной.
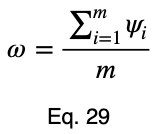
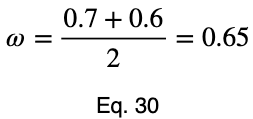
Чтобы учесть, какой вклад вносит вариация каждой факторной переменной в весь набор данных, мы можем взять средневзвешенное значение, где весами являются проценты встречаемости в наборе данных. Мы нормализуем наши веса, разделив каждый из них на его максимальное значение. Пусть 𝜌ᵢ — процент встречаемости каждой из входных переменных, а ϕᵢ — взвешенные нормализованные вариации:
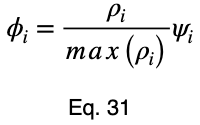
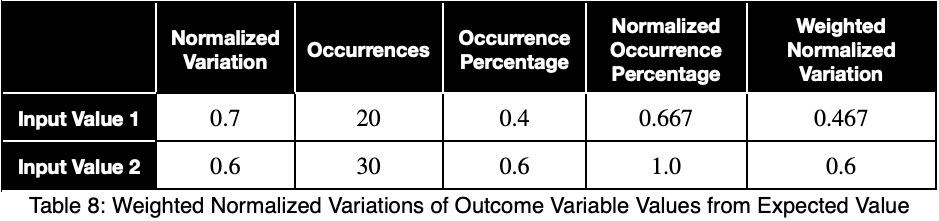
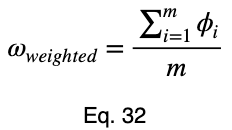
Взяв среднее значение этих показателей, мы получаем взвешенный прогнозный коэффициент.
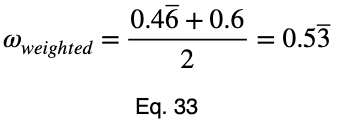
Частные случаи
Давайте посмотрим, как выглядит идеальный предиктор.




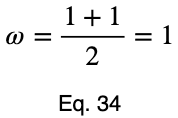
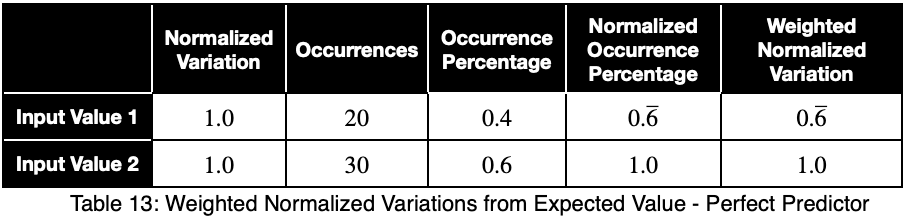
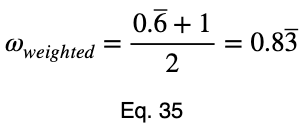
Обратите внимание, что взвешивание приводит к тому, что даже идеальный предиктор имеет значение меньше единицы.
При попытке выявить утечку данных и взаимосвязи между факторными переменными, использование невзвешенного прогнозного коэффициента может быть более показательным. При отборе признаков взвешенный прогнозный коэффициент может дать лучшее описание. Рекомендуется анализировать оба коэффициента.
Рассмотрим равномерный предиктор.




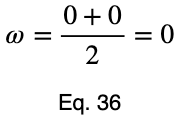
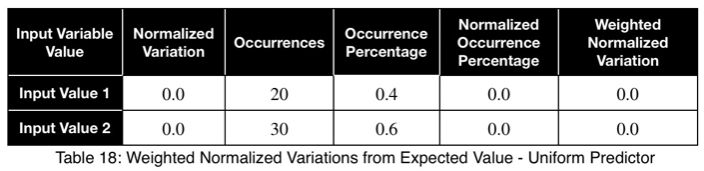
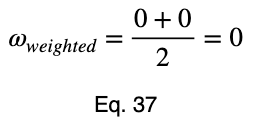
Обратите внимание, что значения ω и взвешенного ω из нашего первого примера, хотя и несколько далеки от единицы, не указывают на плохую предикторную переменную. Наши максимальные проценты появления целевой переменной составили 85 и 80 процентов для первого и второго значений факторной переменной соответственно. Это достаточно сильный предиктор. При сравнении значений многих факторных переменных одновременно, как в корреляционной матрице, относительные значения будут четко указывать, какие из них лучше работают в качестве хороших предикторов.
Чтобы лучше понять, на что указывают эти значения, давайте посмотрим на тенденцию изменения этого прогнозного коэффициента в зависимости от того, как часто встречается одно значение целевой переменной для одного значения факторной переменной.
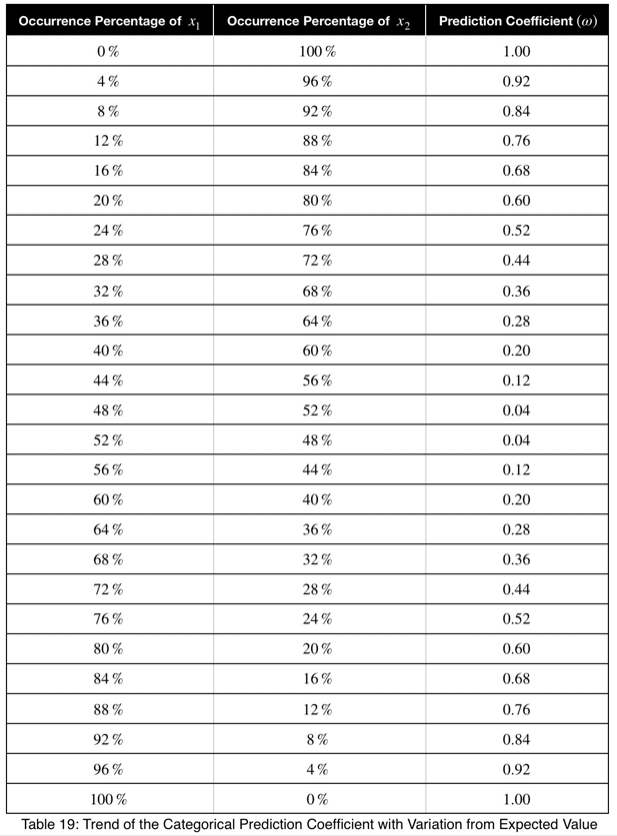
Мы видим, что прогнозный коэффициент равен разнице между x₁ и 1/n при n = 2, умноженной на 2. Таким образом, получив его для пары бинарных переменных, мы можем взять это значение, разделить его на 2, добавить 0,5 и вычислить максимальный процент появления одного из значений целевой переменной. Это точно скажет нам, насколько сильно целевая переменная прогнозируется этой переменной по её проценту появления.
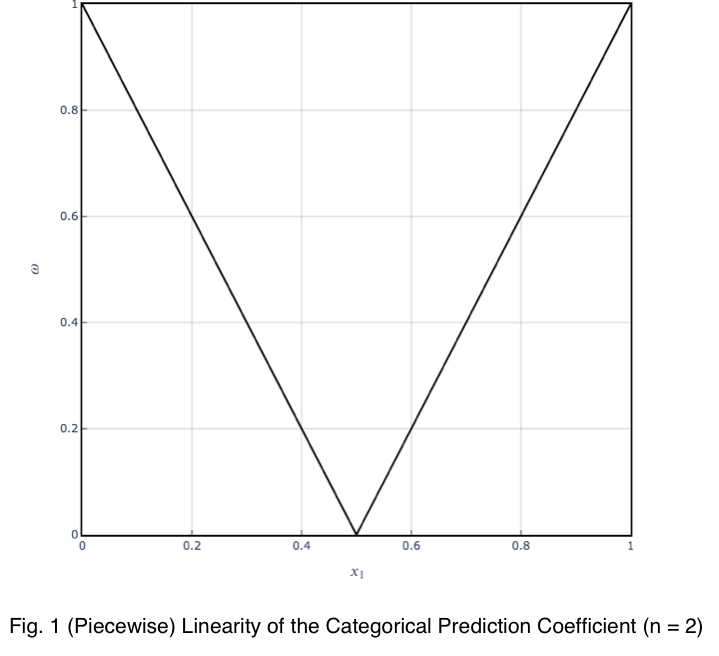
Тенденция линейна, и коэффициент можно использовать с уверенностью.
p-value
Наша нулевая гипотеза заключается в том, что для каждого значения факторной переменной каждое значение целевой переменной является одинаково вероятным. А процент их появления соответствует равномерному распределению. Вероятность появления каждого значения целевой переменной равна вероятности, рассчитанной по функции вероятности мультиномиального распределения(PMF). Значения вероятности бинарной целевой переменной будут соответствовать PMF биномиального распределения, которое является частным случаем мультиномиального распределения. Мы должны вычислить эту вероятность для каждого значения факторной переменной. Затем мы возьмём их среднее значение. Нет необходимости беспокоиться об учёте процента встречаемости для каждого значения. Расчёт вероятности уже учитывает это.
Вот формула для вероятности получения любого числа появлений из общего числа испытаний, которые следуют биномиальному распределению, где каждое значение равновероятно. Чтобы не переопределять переменные, которые мы уже используем, мы немного отклонимся от стандартных обозначений. Пусть t — общее число испытаний, y₁ — число появлений одного значения целевой переменной, y₂ — число появлений другого значения целевой переменной, а P — вероятность получения тех y₁ и y₂, которые мы получили из t испытаний. Напомним, что m — это общее число возможных значений целевой переменной. Нулевая гипотеза гласит, что каждое из этих m значений равновероятно. Поэтому вероятность того, что любое из них произойдет, равна 1/m.
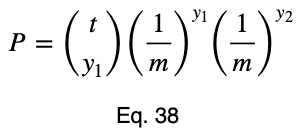
Теперь добавим подстрочный индекс (субскрипт) i для обозначения каждого значения факторной переменной и заменим заглавную букву P на строчную p.
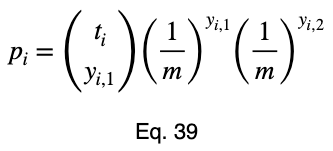
Более общую формулу для мультиномиального распределения мы увидим на примере многоклассовой классификации.
Для нашего первого примера мы имеем:
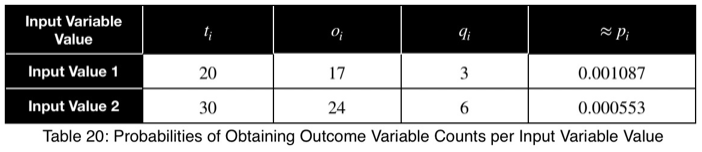
Затем мы берем среднее, чтобы получить p-value.
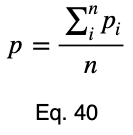

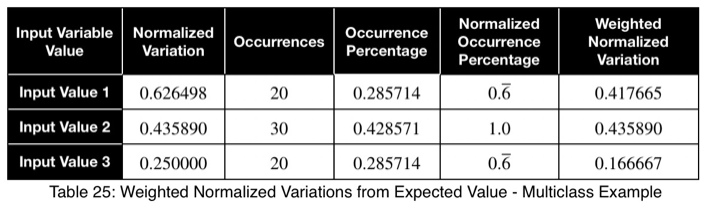
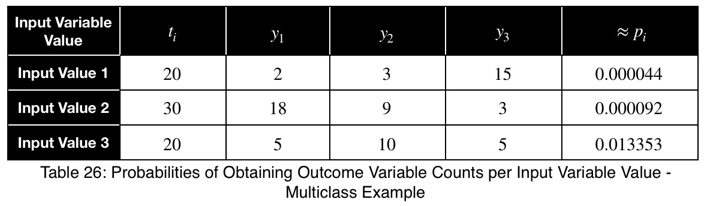
Пример многоклассовой классификации
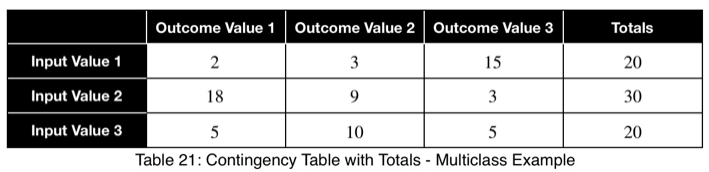
Допустим, в нашем наборе данных есть переменная со следующим количеством факторных и целевых значений.
Используя уравнение 1, мы рассчитываем наше отклонение от ожидаемого значения, которое составляет 1/3 для трёх возможных значений целевой переменной.

Теперь нормализуем путем деления на квадратный корень из (n - 1)/n при n = 3, квадратный корень из 2/3.
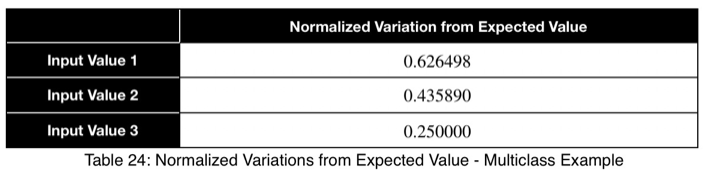

Здесь мы видим значение от 0,4 до 0,5, что указывает на сильный предиктор.

Вот формула для функции вероятности мультиномиального распределения, когда вероятность каждого возможного значения равна 1/m. P — это вероятность, t — общее число значений переменной исхода, а y₁ — yₘ — число случаев появления каждого из m значений переменной исхода.
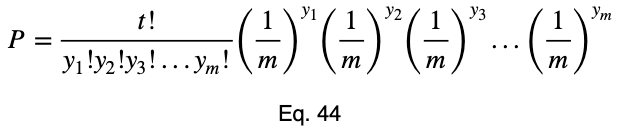
Дополнительную информацию по этой формуле можно получить здесь.
Теперь мы добавим субскрипт i, чтобы отметить, что это делается для каждого из i значений факторной переменной.
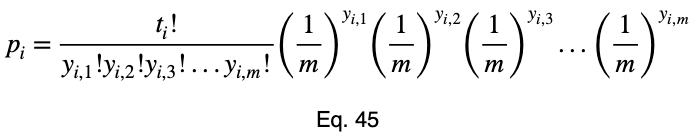
Для целевой переменной с тремя значениями тенденция прогнозного коэффициента с одним процентом появления значения является по существу кусочно-линейной. Если мы разделим оставшийся процент поровну между двумя другими значениями, то получим такой график.
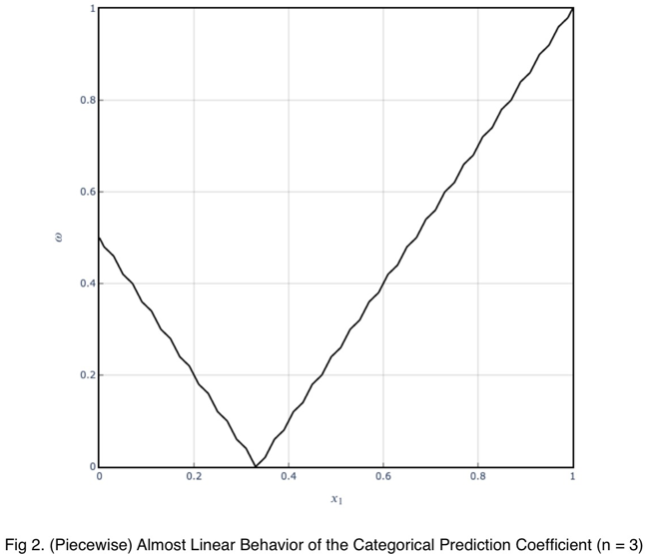
Отклонения от прямой линии — это не то, о чем стоит беспокоиться на практике. Делая оценку на каждые отдельные 4% графика, тенденция будет линейной на каждом из них.
Наше минимальное значение появляется при ожидаемом значении равномерного распределения, 1/3 для целевой переменной с тремя значениями. По мере увеличения числа значений целевой переменной это число стремится к нулю. И значения определяются прямой из начала координат с наклоном в 1.
Корреляционная матрица
Прогнозный коэффициент не является симметричным, но можно увидеть взаимосвязи обоих значений, если построить корреляционную матрицу, в которой факторные переменные находятся по строкам, а целевые по столбцам.
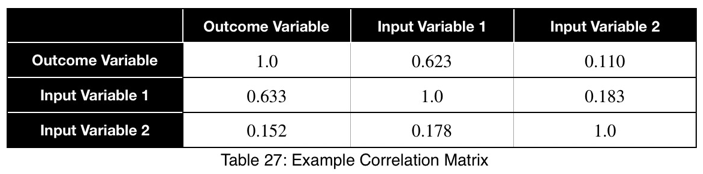
Если отсортируем эту таблицу в порядке убывания по первому столбцу, то получим наши факторные переменные в порядке убывания прогнозной силы. Также наглядно будет видна утечка данных и взаимосвязи между парами факторных переменных. Здесь мы видим, что факторная переменная 1 имеет сильную связь с целевой переменной в обоих направлениях, что может быть признаком утечки данных. Факторная переменная 2 не является сильным предиктором для целевой переменной и не имеет сильной связи с факторной переменной 1.
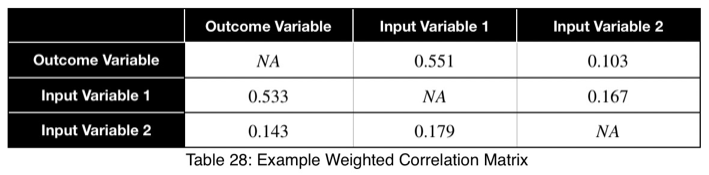
Для взвешенных коэффициентов заменим диагональ на NA.
Заключение
Этот метод предназначен для облегчения обнаружения сильных взаимосвязей между категориальными переменными. Наличие значения в одном масштабе для всех пар переменных позволит гораздо проще, легче и быстрее определить, какие переменные имеют более сильную взаимосвязь, чем другие. Хотя этот коэффициент и называется прогнозным, он говорит нам о том, насколько вариация одной переменной связана с вариацией другой переменной. И по этому числу мы можем судить о том, насколько хорошо одна переменная определяет другую.
Реализация данного алгоритма и способ установки доступны бесплатно на github у автора.
Источник: Medium
Перевод и адаптация: Екатерина Прохорова