Метод главных компонент (PCA) в Python

Проблема проклятия размерности
Чем больше признаков (или "измерений") в наборе данных, тем больше требуется данных для получения статистически значимого результата. Это может привести к следующим проблемам в машинном обучении:
- Переобучение. Модель может показывать хорошее качество на том наборе данных, на котором обучалась, но будет плохо работать на новых данных.
- Увеличение вычислительной сложности. Алгоритмам машинного обучения требуется больше времени для обработки данных с высокой размерностью.
- Снижение качества. Модели машинного обучения могут показывать показывать более низкое значение метрик качества на данных с высокой размерностью.
Всё это принято называть "проклятием размерности". Для борьбы с ним можно применять такие техники:
- Feature selection (отбор признаков): Отбор наиболее важных признаков из набора данных.
- Feature extraction (извлечение признаков): Преобразование исходных признаков в новый набор с меньшей размерностью.
В данной статье будет рассмотрен один из методов feature extraction - "Метод главных компонент" (Principal Component Analysis, PCA).
Введение в метод главных компонент (PCA)
Метод главных компонент был предложен математиком Карлом Пирсоном в 1901 году. Он основан на следующем принципе: при отображении данных из пространства более высокой размерности в пространство меньшей размерности дисперсия данных в новом пространстве должна быть максимальной. PCA основывается на предположении о том, что информация содержится в дисперсии признаков: чем выше дисперсия признака, тем больше информации он несет.
Другими словами, PCA старается сохранить как можно больше информации о данных, при этом уменьшая их размерность, используя ортогональное преобразование для перехода от набора коррелированных переменных к набору некоррелированных переменных.
PCA – это алгоритм машинного обучения без учителя. Это означает, что у нас отсутствует целевая переменная, которую мы прогнозируем. PCA реализуется через поиск основных паттернов данных путем максимизации объясненной дисперсии.
- в исследовательском анализе данных (EDA) для понимания структуры данных и выявления скрытых закономерностей. PCA позволяет отображать высокоразмерные данные в двух или трех измерениях, что упрощает их интерпретацию.
- при построении моделей машинного обучения. PCA может помочь определить наиболее важные признаки с целью уменьшения размера набора данных без потери важной информации.
Важно отметить, что метод главных компонент не всегда является идеальным решением для задачи уменьшения размерности. Например, если между переменными есть нелинейные зависимости, PCA может некорректно отобразить взаимосвязи между ними.
В таких случаях могут быть более подходящими другие методы уменьшения размерности, такие как t-SNE или UMAP.
Пошаговая реализация PCA
В основе PCA лежит техника уменьшения размерности данных, которая:
- Определяет набор ортогональных осей. Эти оси, называемые главными компонентами, максимально отражают разброс данных.
- Ранжирует главные компоненты. Главные компоненты являются линейными комбинациями исходных переменных в наборе данных и упорядочены по убыванию важности.
- Выбирает наиболее важные компоненты. Количество главных компонентов, используемых для представления данных, определяется пользователем.

Шаг 1: Стандартизация
Для начала необходимо стандартизировать набор данных, чтобы у каждого признака среднее значение было в нуле, а стандартное отклонение равно единице. После такого преобразования признаки станут иметь похожий машстаб, а сильно разный масштаб может привести к проблемам при вычислении ковариационной матрицы. Формула стандартизации такая:

, где x̄ - математическое ожидание, которое обычно заменяется просто выборочной оценкой (среднему значению x по выборке), а σ - стандартное отклонение.
Шаг 2: Вычисление матрицы ковариации
Ковариация измеряет силу совместной изменчивости между двумя или более переменными, показывая, насколько они изменяются относительно друг друга. Чтобы найти ковариацию, можно использовать формулу:

Значение ковариации может быть положительным, отрицательным или нулевым.
Положительное: при увеличении x также увеличивается y.
Отрицательное: при увеличении x уменьшается y.
Нулевое: нет прямой связи.
Шаг 3: Вычисление собственных значений и собственных векторов матрицы ковариации для определения главных компонент
Пусть A - квадратная матрица n × n, а X - ненулевой вектор, для которого

для некоторых скалярных значений λ. Тогда λ называется собственным значением матрицы A, а X называется собственным вектором матрицы A для соответствующего собственного значения.

где I - единичная матрица той же формы, что и матрица A. И вышеприведенные условия будут истинными только если (A - λI) будет необратимой (т.е. сингулярной матрицей). Это означает, что

Из вышеприведенного уравнения мы можем найти собственные значения λ, и, следовательно, соответствующие собственные векторы можно найти с помощью уравнения AX = λX.
Метод главных компонент в Python
Все шаги выше можно просто реализовать в Python c помощью библиотеки scikit-learn.
Для стандартизации данных можно воспользовываться классом StandardScaler из модуля sklearn.preprocessing. А при создании экземпляра класса PCA и вызыве метода fit() автоматически вычисляетcя ковариационная матрица и вычисляются собственные значения и векторы матрицы. Эти собственные значения и векторы используются для проецирования данных на новое пространство признаков, где компоненты упорядочены по убыванию доли объясненной дисперсии.
Давайте рассмотрим реализацию алгоритма прогнозирования волатильности индекса VIX с помощью машинного обучения и метода главных компонент.
Индекс волатильности VIX, также известный как индекс страха или индекс финансовой волатильности, измеряет ожидаемую волатильность рынка на основе цен опционов на S&P 500. Он часто используется как индикатор настроений и ожиданий на фондовом рынке. Предсказание индекса VIX помогает инвесторам и трейдерам адаптироваться к изменяющимся условиям рынка, прогнозировать риски и принимать более обоснованные решения о своих инвестициях и стратегиях торговли.
Для начала рассмотрим алгоритм прогнозирования, обученный без применения метода глваных компонент.
Шаг 1: Импорт библиотек и загрузка данных
Импортируем необходимые библиотеки и загружаем данные об индексе волатильности VIX с помощью библиотеки yfinance:
import yfinance as yf
import pandas as pd
# Загрузка данных VIX с 1 января 2000 года по 25 апреля 2024 года
data = yf.download("^VIX", "2000-01-01", "2024-04-25mplted
# Выведем размерность датафрейма и последние 5 строк
df = data.copy()
print(df.shape)
df.tail(5)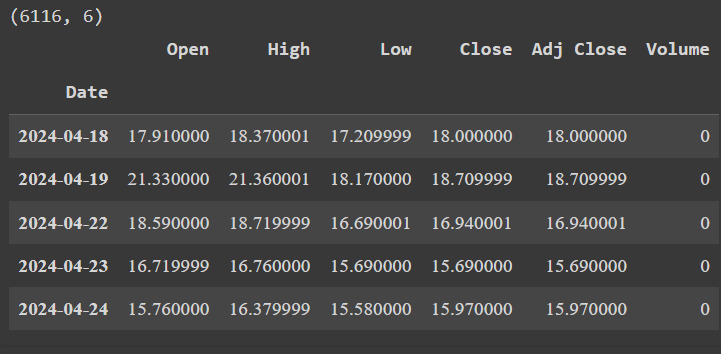
Шаг 2: Добавление технических индикаторов
Добавим технические индикаторы к данным с помощью библиотеки ta. Библиотека ta не встроена в Python по умолчанию, поэтому её необходимо предварительно установить.
# Установка библиотеки ta
!pip install ta
# Добавление технических индекаторов
from ta import add_all_ta_features
df = add_all_ta_features(df,
open="Open", high="High",
low="Low", close="Adj Close",
volume="Volume", fillna=True)
df.tail(3)
После добавления технических индекаторов, количество признаков с 6 увеличилось до 92.
Шаг 3: Подготовка данных для обучения модели
Определим целевую переменную для обучения модели:
# Если цена актива увеличилась на следующий день, # то значение "TARGET" для этой строки будет равно 1. # В остальных случаях значение "TARGET" остётся 0. df["TARGET"] = 0 df.loc[df["Adj Close"].shift(-1) > df["Adj Close"], "TARGET"] = 1 df.head(3)

Разделим данные на признаки (X) и целевую переменную (y), выполним стандартизацию признаков и разделим на обучающий и тестовый выборки:
from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split # Признаки X = df.iloc[:, :-1] # все строки и все столбцы кроме последнего столбца ["TARGET"] # Целевой признак y = df.iloc[:, -1] # выбираем последний столбец ["TARGET"] # Разделение на тренировочную и тестовую выборки X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y) # Стандартизация данных scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)
Шаг 4: Инициализация и обучение модели RandomForest
Инициализируем и обучаем модель RandomForest с оценкой на кросс-валидации:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_validate, StratifiedKFold
from sklearn.metrics import make_scorer, precision_score, recall_score, f1_score, accuracy_score
import numpy as np
# Определение метрик для оценки
scoring = {'precision': make_scorer(precision_score, average='weighted'),
'recall': make_scorer(recall_score, average='weighted'),
'f1_score': make_scorer(f1_score, average='weighted'),
'accuracy': make_scorer(accuracy_score)}
# Инициализация модели
model = RandomForestClassifier(random_state=42, class_weight='balanced', max_depth=5)
# Создание стратифицированных фолдов
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# Выполнение кросс-валидации с оценкой
cv_results = cross_validate(model, X_train_scaled, y_train, cv=skf, scoring=scoring)
# Вычисление средних значений метрик
avg_precision = np.mean(cv_results['test_precision'])
avg_recall = np.mean(cv_results['test_recall'])
avg_f1_score = np.mean(cv_results['test_f1_score'])
avg_accuracy = np.mean(cv_results['test_accuracy'])
# Вычисление среднего времени обучения
avg_train_time = np.mean(cv_results['fit_time'])
# Вывод результатов
print("Среднее значение precision на кросс-валидации:", avg_precision)
print("Среднее значение recall на кросс-валидации:", avg_recall)
print("Среднее значение F1-score на кросс-валидации:", avg_f1_score)
print("Среднее значение accuracy на кросс-валидации:", avg_accuracy)
print("Среднее время обучения на одну модель:", avg_train_time, "секунд")
# Среднее значение precision на кросс-валидации: 0.5546306080708816
# Среднее значение recall на кросс-валидации: 0.552537646402677
# Среднее значение F1-score на кросс-валидации: 0.5527705938334151
# Среднее значение accuracy на кросс-валидации: 0.552537646402677
# Среднее время обучения на одну модель: 1.6854261875152587 секундОбучим модель на всей тренировочной выборке и сделаем прогноз на тестовой:
from sklearn.metrics import classification_report
# Обучение модели на тренировочных данных
model.fit(X_train_scaled, y_train)
# Прогнозирование меток классов для тренировочных и тестовых данных
y_train_pred = model.predict(X_train_scaled)
y_test_pred = model.predict(X_test_scaled)
# Вывод отчета классификации
print('Прогнозирование меток классов для тренировочных данных:', classification_report(y_train, y_train_pred), sep='\n')
print('---' * 20)
print('Прогнозирование меток классов для тестовых данных:', classification_report(y_test, y_test_pred), sep='\n')
Вывод
Прогнозирование меток классов для тренировочных данных:
precision recall f1-score support
0 0.69 0.64 0.66 2655
1 0.61 0.65 0.63 2237
accuracy 0.65 4892
macro avg 0.65 0.65 0.65 4892
weighted avg 0.65 0.65 0.65 4892
------------------------------------------------------------
Прогнозирование меток классов для тестовых данных:
precision recall f1-score support
0 0.59 0.54 0.56 664
1 0.50 0.55 0.53 560
accuracy 0.55 1224
macro avg 0.55 0.55 0.55 1224
weighted avg 0.55 0.55 0.55 1224
Построим матрицу ошибок для визуализации предсказаний модели:
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# Вычисление матрицы ошибок
conf_matrix = confusion_matrix(y_test, y_test_pred)
# Визуализация матрицы ошибок в виде тепловой карты
plt.figure(figsize=(6, 4))
sns.heatmap(conf_matrix, annot=True, cmap='Blues', fmt='g')
plt.xlabel('Предсказанные метки')
plt.ylabel('Истинные метки')
plt.title('Матрица ошибок')
plt.show()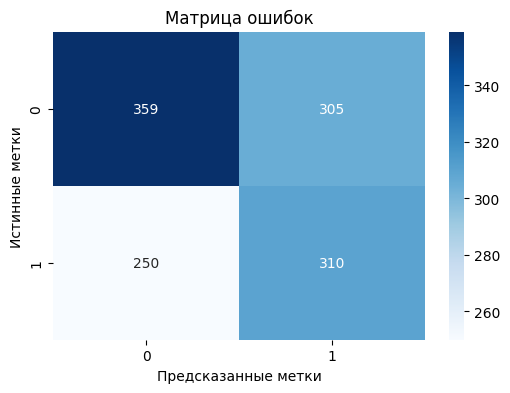
Средние значения метрик (precision, recall, F1-score, accuracy) на кросс-валидации составляют около 0.55.
Качество модели на тренировочных данных существенно отличается от тестовых, что указывает на склонность модели к переобучению.
Попробуем уменьшить количество признаков с помощью метода главных компонент и обучить модель RandomForest с теме же параметрами.
Шаг 5: Использование метода главных компонент для уменьшения размерности данных
Применим PCA для уменьшения размерности данных и обучим модель RandomForest на преобразованных данных:
Импортируем PCA из модуля sklearn.decomposition, обучим PCA и визуализируем информацию о компонентах:
from sklearn.decomposition import PCA
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 6)) # Устанавливаем размер фигуры
pca = PCA().fit(X_train_scaled)
n_components = pca.explained_variance_ratio_.shape[0]
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xticks(np.arange(0, n_components + 1, step=5)) # Устанавливаем шаг на оси X
plt.xlabel('Количество компонентов')
plt.ylabel('Объясненная дисперсия')
plt.show()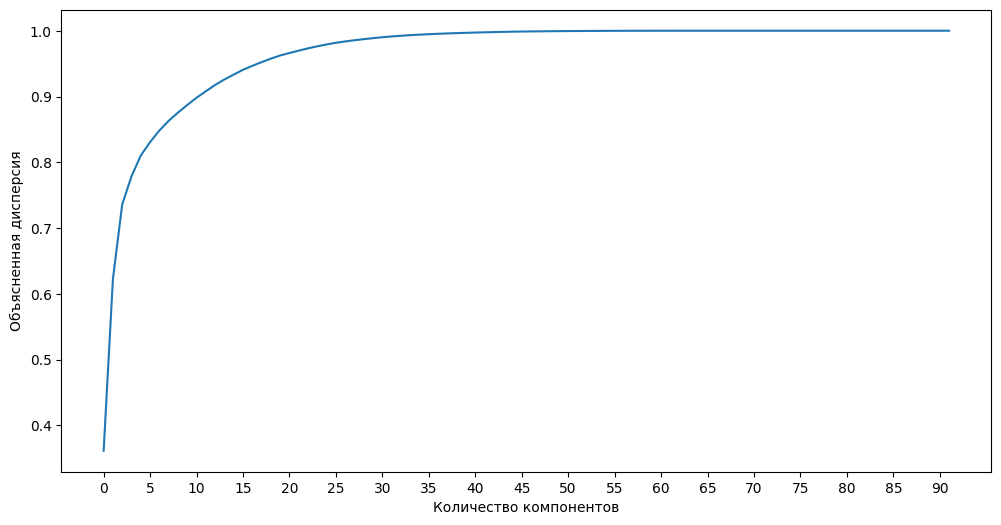
По граифику видно, что всего 10 компонентов из 92 объясняют порядка 90% информации в данных. Оставим эти 10 компонентов для обучения модели:
# Установим важные компоненты:
components = 10
# Применим преобразование метода главных компонент
# к стандартизированным данным,
# уменьшая их размерность до количества компонент(десяти)
pca = PCA(n_components=components)
X_pca_train = pca.fit_transform(X_train_scaled)
X_pca_test = pca.fit_transform(X_test_scaled)
# Вычисление дисперсии, объясненной главными компонентами
print("Дисперсия каждой компоненты: ", pca.explained_variance_ratio_)
print("\n Общая объясненная дисперсия: ", round(sum(list(pca.explained_variance_ratio_)) * 100, 2))
# Дисперсия каждой компоненты: [0.40694312 0.23286115 0.11066324 0.0408183 0.02880789 0.02064323
# 0.01907965 0.01391021 0.01147294 0.01108834]
# Общая объясненная дисперсия: 89.63Визуализируем главные компоненты:
# Названия столбцов после применения PCA
pca_cols = []
for i in range(components):
pca_cols.append(f"PC_{i}")
print(pca_cols)
# ['PC_0', 'PC_1', 'PC_2', 'PC_3', 'PC_4', 'PC_5', 'PC_6', 'PC_7', 'PC_8', 'PC_9']
# Создание DataFrame
pca_df = pd.DataFrame(X_pca, columns=pca_cols)
pca_df.head()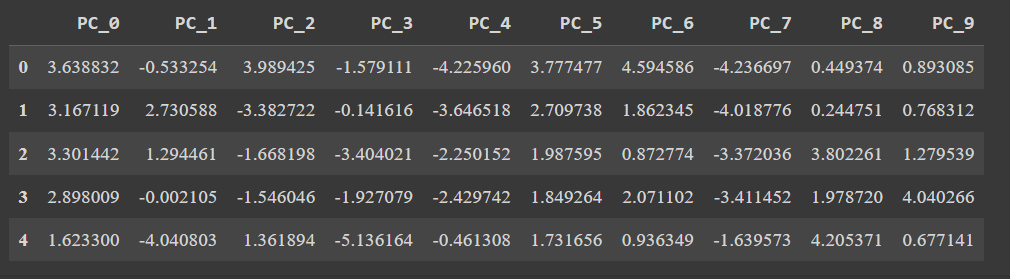
Визуализируем распределение данных в пространстве первых двух главных компонент:
# scatter plot для первых двух компонент PCA
plt.figure(figsize=(12, 6))
plt.scatter(X_pca_train[:, 0], X_pca_train[:, 1], c=y_train, alpha=0.75)
plt.xlabel('PC_0')
plt.ylabel('PC_1')
plt.title('Визуализация компонент PCA')
plt.colorbar(label='Целевая переменная')
plt.show()
А теперь обучим модель на уменьшеной размерности данных:
# Определение метрик для оценки
scoring = {'precision': make_scorer(precision_score, average='weighted'),
'recall': make_scorer(recall_score, average='weighted'),
'f1_score': make_scorer(f1_score, average='weighted'),
'accuracy': make_scorer(accuracy_score)}
# Инициализация модели
model = RandomForestClassifier(random_state=42, class_weight='balanced', max_depth=5)
# Создание стратифицированных фолдов
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# Выполнение кросс-валидации с оценкой
cv_results = cross_validate(model, X_pca_train, y_train, cv=skf, scoring=scoring)
# Вычисление средних значений метрик
avg_precision = np.mean(cv_results['test_precision'])
avg_recall = np.mean(cv_results['test_recall'])
avg_f1_score = np.mean(cv_results['test_f1_score'])
avg_accuracy = np.mean(cv_results['test_accuracy'])
# Вычисление среднего времени обучения
avg_train_time = np.mean(cv_results['fit_time'])
# Вывод результатов
print("Среднее значение precision на кросс-валидации:", avg_precision)
print("Среднее значение recall на кросс-валидации:", avg_recall)
print("Среднее значение F1-score на кросс-валидации:", avg_f1_score)
print("Среднее значение accuracy на кросс-валидации:", avg_accuracy)
print("Среднее время обучения на одну модель:",rain_time, "секунд")
# Среднее значение precision на кросс-валидации: 0.5396169109902705
# Среднее значение recall на кросс-валидации: 0.5343389084893186
# Среднее значение F1-score на кросс-валидации: 0.5343591653394495
# Среднее значение accuracy на кросс-валидации: 0.5343389084893186
# Среднее время обучения на одну модель: 0.7346380233764649 секундА теперь сделаем прогноз на тестовых данных:
from sklearn.metrics import classification_report
# Обучаем модель
model.fit(X_pca_train, y_train)
# Прогнозирование меток классов для тестовых данных
y_train_pred = model.predict(X_pca_train)
y_test_pred = model.predict(X_pca_test)
# Вывод отчета классификации
print('Прогнозирование меток классов для тренировочных данных:', classification_report(y_train, y_train_pred), sep='\n')
print('---' * 20)
print('Прогнозирование меток классов для тестовых данных:', classification_report(y_test, y_test_pred), \n')
Прогнозирование меток классов для тренировочных данных:
precision recall f1-score support
0 0.68 0.57 0.62 2655
1 0.57 0.67 0.62 2237
accuracy 0.62 4892
macro avg 0.62 0.62 0.62 4892
weighted avg 0.63 0.62 0.62 4892
------------------------------------------------------------
Прогнозирование меток классов для тестовых данных:
precision recall f1-score support
0 0.61 0.52 0.56 664
1 0.52 0.61 0.56 560
accuracy 0.56 1224
macro avg 0.57 0.57 0.56 1224
weighted avg 0.57 0.56 0.56 1224
И построим матрицу ошибок для визуализации предсказаний модели:
conf_matrix = confusion_matrix(y_test, y_test_pred)
plt.figure(figsize=(6, 4))
sns.heatmap(conf_matrix, annot=True, cmap='Blues', fmt='g')
plt.xlabel('Предсказанные метки')
plt.ylabel('Истинные метки')
plt.title('Матрица ошибок')
plt.show()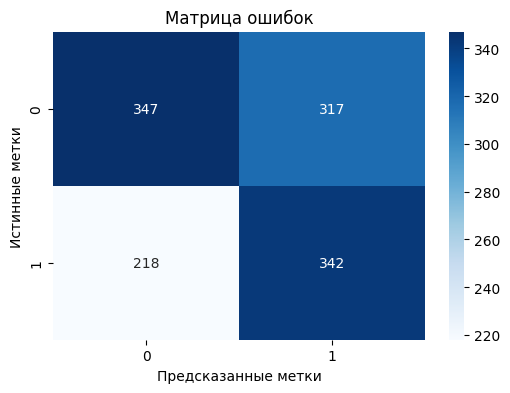
Данная модель на кросс-валидации показывает результаты с некоторым ухудшением по сравнению с предыдущей моделью. Средние значения метрик (precision, recall, F1-score, accuracy) на кросс-валидации составляют около 0.53 против 0.55.
На тренировочных данных модель без применения PCA также демонстрирует более высокие показатели precision, recall и F1-score для обоих классов, а также более высокую точность (accuracy) по сравнению с моделью с применением метода главныз компонент.
Однако на тестовых данных обе модели показывают схожие результаты по точности. Модель с применением метода главных компонент демонстрирует немного выше значения метрик accuracy, precision, recall и F1-score для класса 1 в то время как модель с PCA имеет немного более высокий показатель метрики recall для класса 0.
Вот итоговые метрики на тестовой выборке:

В данном случае применение PCA не привело к значительному улучшению качества модели, изменения в метриках незначительны и могут быть вызваны случайностью. Однако время обучения значительно сократилось (без применения метода главных компонент среднее время обучения на кросс-валидации: 1.685 сек, с применением – 0.734 сек.), что может быть важным фактором при работе с большими объемами данных.
Заключение
PCA – это алгоритм машинного обучения без учителя, который преобразует данные в новое пространство с меньшим количеством признаков, сохраняя при этом максимум информации.
- Снижение переобучения: уменьшая размерность данных, PCA уменьшает риск переобучения модели.
- Повышение производительности: алгоритмы машинного обучения работают быстрее с меньшим количеством признаков.
PCA является хорошим инструментом для решения проблемы проклятия размерности и повышения точности моделей машинного обучения. Однако важно помнить, что эффективность метода главных компонент может варьироваться в зависимости от задач и необходимо тщательно оценивать влияние PCA на конкретную задачу.
👉🏻Подписывайтесь на PythonTalk в Telegram 👈🏻
Автор: Дмитрий Каленов