Polars: альтернатива Pandas для анализа данных в Python

Если вы работаете с данными в Python, то, скорее всего, хорошо знакомы с библиотекой Pandas. Уже очень долго она является стандартом в data science. Да, Pandas популярен, очень хорош для множества задач, но когда дело доходит до действительно больших объемов данных или сложных, многошаговых вычислений, его производительность и аппетиты к оперативной памяти могут стать узким местом.
Есть ли у нас альтернатива, спроектированная с нуля с упором на максимальную производительность? Встречайте Polars — относительно новую библиотеку для работы с датафреймами, написанную на Rust и быстро набирающую популярность.
Почему стоит обратить внимание на Polars?
Polars была создана в 2021 году специально для решения проблем, которые есть в Pandas. Какие у неё особенности?
- Высокая производительность. В основе Polars лежит ядро, написанное на Rust. Этот язык известен своей производительностью, сравнимой с C/C++, и строгой системой управления памятью без сборщика мусора. Polars активно использует формат Apache Arrow для представления данных в памяти. Arrow — это не просто формат, а целая платформа для эффективной обработки данных в памяти, основанная на столбцовом (колоночном) хранении. Это минимизирует затраты на сериализацию/десериализацию и позволяет использовать оптимизированные SIMD-инструкции процессора (векторизованные вычисления). В результате многие операции в Polars выполняются значительно быстрее, чем их аналоги в Pandas, особенно на больших объемах данных.
- Многопоточность "из коробки". Библиотека изначально спроектирована для распараллеливания вычислений. Нам не нужно вручную настраивать multiprocessing или использовать сторонние библиотеки для базовых операций — Polars автоматически попытается задействовать все доступные ядра CPU для ускорения фильтрации, агрегации и других преобразований.
- Ленивые вычисления (Lazy Evaluation). В отличие от "жадного" подхода Pandas, где каждая команда выполняется немедленно, Polars предлагает "ленивый" API. При использовании этого API цепочка ваших команд не выполняется сразу, а формирует план запроса. Polars затем анализирует и оптимизирует этот план перед фактическим выполнением — например, он может переставить операции местами для большей эффективности (скажем, применив фильтры как можно раньше, чтобы сократить объем данных) или объединить несколько шагов в один.
- Эффективное управление памятью. Помимо использования Apache Arrow, Polars стремится минимизировать ненужное копирование данных во время операций. Данные внутри датафрейма также могут обрабатываться блоками (чанками), что улучшает использование кэша процессора и способствует более экономному расходованию памяти.
- Работа с данными больше ОЗУ (Out-of-Core). Благодаря ленивым вычислениям и оптимизированному доступу к данным (включая специальный режим сканирования файлов, о котором позже), Polars способен обрабатывать наборы данных, которые физически не помещаются в оперативную память. Он считывает и обрабатывает информацию по частям, выполняя оптимизированный запрос без необходимости загружать весь датасет целиком.
- Консистентный API. Разработчики Polars приложили усилия для создания более последовательного и предсказуемого интерфейса, пытаясь избежать некоторых неоднозначностей, иногда встречающихся в Pandas. Отсутствие сложной системы индексов (как в Pandas) также многим кажется упрощением. Хотя к новому API нужно привыкнуть, многие находят его логичным и удобным в долгосрочной перспективе.
В совокупности эти особенности делают Polars весьма привлекательным инструментом для задач, где критичны скорость обработки, эффективное использование ресурсов и способность работать с по-настоящему большими объемами данных.
Установка и первые шаги
Как и большинство пакетов Python, Polars можно установить с помощью pip:
pip install polars
Polars имеет ряд дополнительных зависимостей для поддержки различных форматов файлов (Parquet, Excel, баз данных и т.д.) и оптимизаций. Можно установить сразу со всем вместе:
pip install polars[all]
После этого делаем импорты, стандартное соглашение — использовать псевдоним pl:
import polars as pl
Основная структура данных в Polars, как и в Pandas, — это DataFrame. Это двумерная табличная структура со строками и именованными столбцами. Столбцы в Polars представлены объектами Series.
Polars поддерживает множество форматов. Например, для чтения CSV-файла с данными о продажах можно использовать pl.read_csv().
# Попытка прочитать реальный файл
try:
df_sales = pl.read_csv(
"sales_data.csv",
try_parse_dates=True, # Пытаемся распознать даты
dtypes={"quantity": pl.Int32} # Явно указываем тип для quantity
)
print("Данные успешно загружены из 'sales_data.csv'")
except FileNotFoundError:
# Если файла нет, создадим набор данных для примеров
print("Файл 'sales_data.csv' не найден. Создаем демонстрационный DataFrame.")
df_sales = pl.DataFrame({
"order_id": [101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115],
"customer_name": ["Анна", "Борис", "Анна", "Виктор", "Борис", "Дарья", "Анна", "Борис", "Виктор", "Анна", "Дарья", "Борис", "Виктор", "Анна", "Дарья"],
"product_sku": ["АРТ-А1", "АРТ-Б2", "АРТ-В1", "АРТ-А1", "АРТ-Б2", "АРТ-Г3", "АРТ-А1", "АРТ-В1", "АРТ-Б2", "АРТ-В1", "АРТ-Г3", "АРТ-А1", "АРТ-Г3", "АРТ-Б2", "АРТ-А1"],
"quantity": pl.Series([10, 5, 8, 12, 6, 15, 7, 9, 11, 4, 18, 10, 20, 6, 9], dtype=pl.Int32), # Явно задаем тип Int32
"price": [1550.0, 2200.0, 875.5, 1550.0, 2200.0, 3100.0, 1550.0, 875.5, 2200.0, 875.5, 3100.0, 1550.0, 3100.0, 2200.0, 1550.0],
"order_date": [
"2025-01-15", "2025-01-20", "2025-02-10", "2025-02-12", "2025-02-18",
"2025-02-25", "2025-03-05", "2025-03-11", "2025-03-15", "2025-03-22",
"2025-04-01", "2025-04-02", "2025-04-10", "2025-04-15", "2025-04-20"
]
# Важный шаг: преобразуем строки с датами в тип Date
}).with_columns(pl.col("order_date").str.strptime(pl.Date, "%Y-%m-%d"))
# Посмотрим на результат
print(df_sales)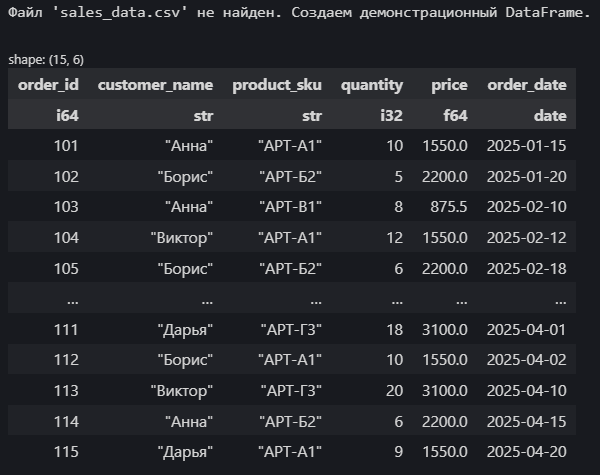
Здесь мы сначала пытаемся загрузить данные из CSV. Если файла нет, создаём датафрейм вручную из словаря. Обратим внимание:
- Мы явно задаем тип
pl.Int32для столбцаquantity. - После создания датафрейма из словаря, столбец
order_date содержит строки. Мы используем метод.with_columns()и выражениеpl.col("order_date").str.strptime(pl.Date, "%Y-%m-%d")для преобразования этих строк в настоящий тип данных Date в Polars.
Polars предлагает знакомые по Pandas методы для первичного знакомства с данным. Например, атрибут .shape возвращает кортеж (количество строк, количество столбцов).
print(f"\nРазмер датафрейма: {df_sales.shape}")
# Вывод: Размер датафрейма: (15, 6)Методы .head(n) и .tail(n) показывают первые и последние n строк (по умолчанию 5):
print("\nПервые 5 строк:")
display(df_sales.head())
print("\nПоследние 3 строки:")
display(df_sales.tail(3))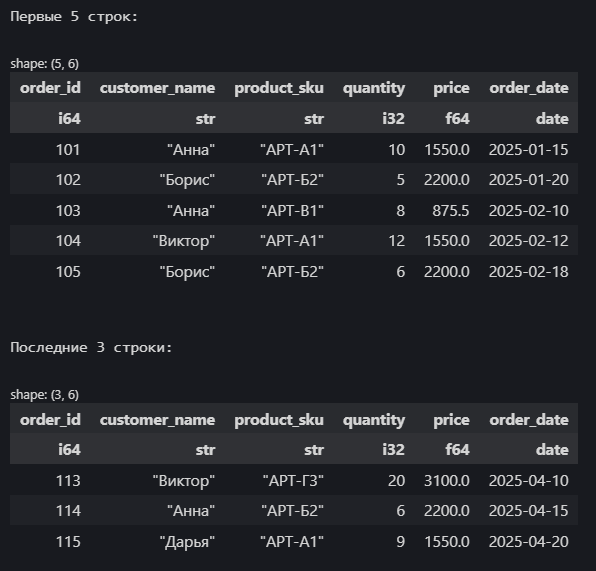
Обратим внимание на вывод: Polars показывает размерность (15, 6), типы данных под именами столбцов (i64 для order_id, str для customer_name, i32 для quantity, f64 для price, date для order_date), а строковые значения заключены в кавычки.
Метод .describe() вычисляет основные статистические показатели для числовых и некоторых других типов столбцов (например, дат):
print("\nОписательная статистика:")
display(df_sales.describe())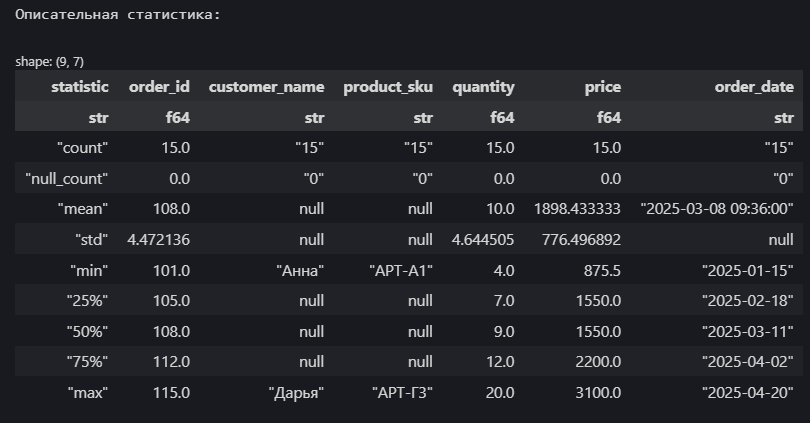
Атрибут .schema показывает имена всех столбцов и их типы данных в Polars:
print("\nСхема датафрейма:")
print(df_sales.schema)Схема датафрейма:
Schema({'order_id': Int64, 'customer_name': String, 'product_sku': String, 'quantity': Int32, 'price': Float64, 'order_date': Date})Основные операции в Polars: выражения и контексты
Центральное место в работе с данными в Polars занимают выражения (expressions). По сути, это описание вычисления или преобразования, которое мы хотим применить к данным, чаще всего к столбцам датафрейма. Выражения строятся с использованием функций и методов Polars, таких как pl.col(), pl.sum(), pl.when() и многих других.
Эти выражения затем выполняются в определенных контекстах. Основные контексты, которые мы рассмотрим:
select(): выборка и преобразование существующих столбцов.filter(): отбор строк на основе условий.with_columns(): добавление или модификация столбцов.group_by().agg(): группировка данных и вычисление агрегированных значений.
Давайте посмотрим, как это работает на примере нашего df_sales.
Выборка столбцов
Метод select() используется для выбора одного или нескольких столбцов из датафрейма. Можно просто передать имена столбцов или использовать выражения pl.col() для более сложных манипуляций, включая переименование с помощью .alias().
# Выбираем только имя клиента, артикул и дату заказа
df_selected = df_sales.select(
pl.col("customer_name"),
pl.col("product_sku"),
pl.col("order_date")
)
print("\nВыборка трех столбцов:")
display(df_selected.head(3))
# Выборка с переименованием
df_renamed = df_sales.select(
pl.col("customer_name").alias("Клиент"),
pl.col("product_sku").alias("Артикул"),
pl.col("quantity").alias("Количество")
)
print("\nВыборка с переименованием:")
display(df_renamed.head(3))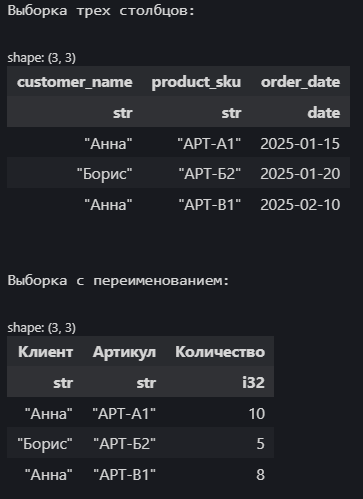
pl.col("имя_столбца") создает выражение, ссылающееся на столбец. Метод .alias() позволяет задать новое имя для выбранного столбца в результирующем датафрейме.
Фильтрация строк
Метод filter() позволяет отбирать строки, соответствующие заданным условиям. Условия создаются с помощью выражений Polars.
# Найти заказы с количеством больше 10
df_filtered_qty = df_sales.filter(
pl.col("quantity") > 10
)
print("\nЗаказы с количеством > 10:")
display(df_filtered_qty.head(3))
# Найти заказы клиента "Анна"
df_filtered_anna = df_sales.filter(
pl.col("customer_name") == "Анна"
)
print("\nЗаказы клиента Анна:")
display(df_filtered_anna.head(3))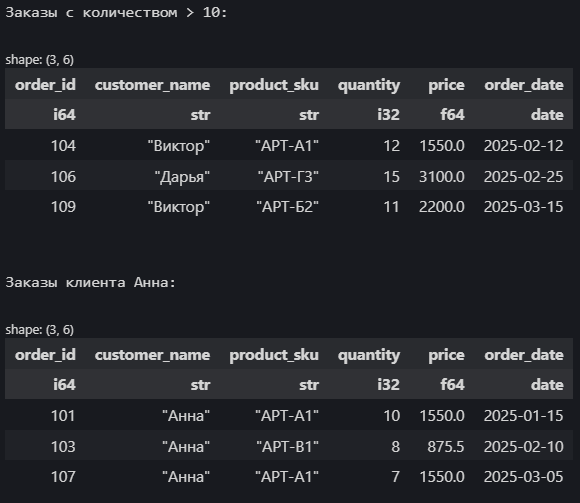
Можем сделать фильтрацию по нескольким условия:
# Найти заказы Бориса ИЛИ Виктора (ИЛИ: |), сделанные ПОСЛЕ 1 марта 2025 (И: &)
df_complex_filter = df_sales.filter(
(pl.col("customer_name").is_in(["Борис", "Виктор"])) &
(pl.col("order_date") > pl.date(2025, 3, 1)) # Сравнение с датой
)
print("\nЗаказы Бориса или Виктора после 2025-03-01:")
display(df_complex_filter)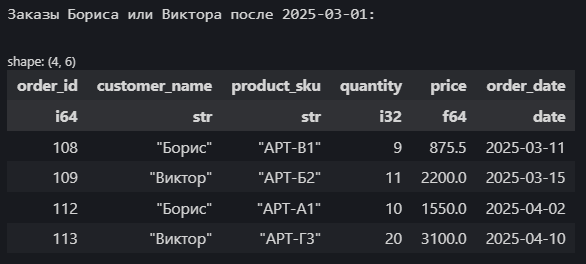
Здесь мы использовали операторы сравнения (>, ==), метод .is_in() для проверки вхождения в список, логические операторы & (И) и | (ИЛИ), а также функцию pl.date() для создания объекта даты для сравнения.
Добавление и изменение столбцов
Метод with_columns() позволяет создавать новые столбцы на основе существующих данных. Также есть удобные методы when().then().otherwise(), эта конструкция аналогична if-then-else в Python и заменяют mask или np.where из Pandas . А функция pl.lit() используется для присвоения литерального значения.
df_new_cols = df_sales.with_columns(
# 1. Создаем столбец 'total_price' (Общая стоимость = количество * цена)
(pl.col("quantity") * pl.col("price")).alias("total_price"),
# 2. Извлекаем месяц из даты заказа
pl.col("order_date").dt.month().alias("order_month"),
# 3. Добавляем категорию товара на основе SKU
pl.when(pl.col("product_sku").str.starts_with("АРТ-А"))
.then(pl.lit("Категория А")) # pl.lit() создает литеральное (константное) значение
.when(pl.col("product_sku").str.starts_with("АРТ-Б"))
.then(pl.lit("Категория Б"))
.when(pl.col("product_sku").str.starts_with("АРТ-В"))
.then(pl.lit("Категория В"))
.otherwise(pl.lit("Другая Категория")) # Для всех остальных случаев (АРТ-Г3)
.alias("sku_category"),
# 4. Добавляем флаг "Крупный заказ" (количество >= 10)
(pl.col("quantity") >= 10).alias("is_large_order") # Результат будет булевым (True/False)
)
print("\nДатафрейм с новыми столбцами:")
display(df_new_cols.head())
print("\nСхема обновленного датафрейма:")
print(df_new_cols.schema)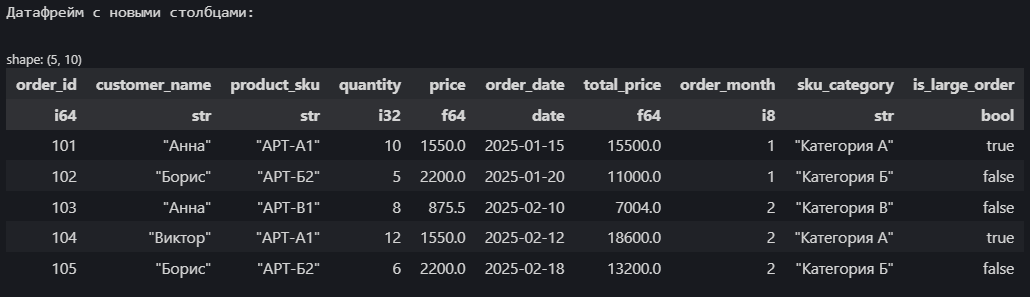
Схема обновленного DataFrame:
Schema({'order_id': Int64, 'customer_name': String, 'product_sku': String, 'quantity': Int32, 'price': Float64, 'order_date': Date, 'total_price': Float64, 'order_month': Int8, 'sku_category': String, 'is_large_order': Boolean})Обратим внимание на .alias("new_name") — так задается имя для новой или измененной колонки. Также важно помнить: операции Polars по умолчанию не изменяют исходный датафрейм,, а возвращают новый. Чтобы сохранить результат, его нужно присвоить переменной (df_new_cols = ...).
Группировка и агрегация
Группировка в Polars похожа на Pandas, но результат отличается.
# Используем датафрейм с новыми столбцами из предыдущего шага
df_grouped = df_new_cols.group_by("customer_name").agg(
pl.sum("quantity").alias("total_quantity_per_customer"), # Суммарное кол-во товаров
pl.sum("total_price").alias("total_value_per_customer"), # Общая сумма заказов
pl.mean("price").alias("average_item_price_per_customer"), # Средняя цена купленного товара
pl.len().alias("order_count_per_customer"), # Количество заказов (строк) в группе
pl.n_unique("product_sku").alias("unique_skus_per_customer"), # Кол-во уникальных артикулов
pl.sum("is_large_order").alias("large_orders_count") # Считаем кол-во крупных заказов (True=1, False=0)
).sort("total_value_per_customer", descending=True) # Сортируем результат по сумме
print("\nСгруппированные данные по покупателям (отсортировано по сумме):")
display(df_grouped)
Сначала мы указываем столбец (или столбцы в виде списка), по которому нужно группировать данные — group_by("customer_name"). Затем в методе agg() мы передаем список выражений для агрегации. Каждое выражение обычно состоит из функции агрегации (pl.sum, pl.mean, pl.len(), pl.n_unique, pl.min, pl.max, pl.median, pl.std и т.д.), применяемой к определенному столбцу, и .alias() для задания имени результирующему столбцу.
Ключевое отличие от Pandas: результат group_by().agg() не содержит мульти-индекс. Столбцы, по которым шла группировка, становятся обычными столбцами в результирующем датафрейме (как если бы мы применяли as_index=False в Pandas). Это часто упрощает дальнейшую работу, но делает невозможным использование stack/unstack в том же виде, как в Pandas.
Для группировки по временным интервалам существует метод group_by_dynamic (требует сортировки по столбцу с датами).
Цепочки операций
Одним из самых удобных аспектов Polars является возможность объединять несколько операций в цепочки. Это не только делает код более читаемым, но и позволяет движку Polars (особенно в Lazy API) оптимизировать всю цепочку целиком.
Давайте найдём общую стоимость заказов Категории А и Б для каждого покупателя за март 2025. Будем использовать df_new_cols из предыдущего примера.
report = (
df_new_cols
.filter( # Шаг 1: Фильтруем по категории и месяцу
(pl.col("sku_category").is_in(["Категория А", "Категория Б"])) &
(pl.col("order_month") == 3) # Март
)
.group_by("customer_name", "sku_category") # Шаг 2: Группируем по покупателю И категории
.agg( # Шаг 3: Считаем суммарную стоимость и количество
pl.sum("total_price").alias("total_value"),
pl.sum("quantity").alias("total_quantity")
)
.sort("customer_name", "sku_category") # Шаг 4: Сортируем для наглядности
)
print("\nОтчет: Стоимость заказов категорий А и Б за март 2025 по покупателям:")
display(report)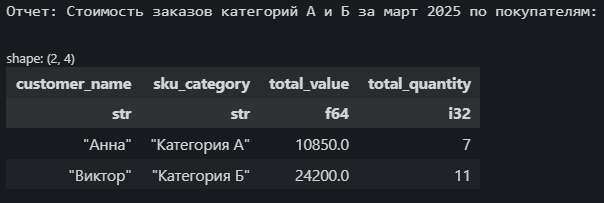
Здесь мы последовательно применили фильтрацию, группировку, агрегацию и сортировку в одной цепочке вызовов. Код читается сверху вниз, описывая последовательность шагов обработки данных.
Работа с Lazy API
До сих пор мы работали в так называемом "жадном" (eager) режиме: каждая операция (filter, with_columns, group_by и т.д.) выполнялась немедленно, создавая (потенциально) новый датафрейм в памяти на каждом шаге. Это похоже на то, как работает Pandas, и удобно для интерактивного анализа.
Однако Polars предлагает и другой, зачастую более эффективный подход — ленивые вычисления (Lazy API).
Основная идея ленивых вычислений — не выполнять работу до тех пор, пока это абсолютно необходимо. Когда мы работаем в ленивом режиме, происходит следующее:
- Сначала строится логический план запроса. Вместо немедленного выполнения каждой операции Polars просто записывает последовательность шагов, которые нужно будет выполнить.
- Затем, перед фактическим выполнением, Polars пропускает этот план через свой оптимизатор запросов. Оптимизатор анализирует весь план целиком и применяет различные стратегии для повышения эффективности. Например, он может переместить операции фильтрации (
filter) как можно ближе к источнику данных, чтобы уменьшить объем обрабатываемой информации на последующих этапах (это называется Predicate Pushdown). Он также может выбрать только необходимые столбцы (select) как можно раньше (Projection Pushdown), упростить арифметические или логические выражения, или даже объединить несколько операций в одну. - Такой подход обеспечивает эффективность по памяти. Поскольку промежуточные датафреймы не создаются на каждом шаге, ленивый API значительно экономит оперативную память, что особенно важно в длинных цепочках преобразований.
- Наконец, оптимизация и экономия памяти делают Lazy API эффективными для работы с большими данными. Он позволяет обрабатывать наборы данных, которые не помещаются или с трудом помещаются в ОЗУ, так как Polars может выполнять оптимизированный запрос, не загружая все данные сразу.
Строим ленивый запрос
Самый простой способ переключиться в ленивый режим для существующего датафрейма — использовать метод .lazy():
# Возьмем наш датафрейм с добавленными столбцами из предыдущего раздела lazy_df_sales = df_new_cols.lazy() print(type(lazy_df_sales)) # <class 'polars.lazyframe.frame.LazyFrame'> print(lazy_df_sales) # naive plan: (run LazyFrame.explain(optimized=True) to see the optimized plan) # DF ["order_id", "customer_name", "product_sku", "quantity", ...]; PROJECT */10 COLUMNS
Теперь lazy_df_sales — это не DataFrame, а LazyFrame. Он содержит описание данных (схему) и начальный план запроса, но сами данные еще не обработаны.
Можно применять те же методы (filter, with_columns, group_by, agg, sort и т.д.), что и к обычному датафрейму, но теперь они будут лишь добавлять шаги в план запроса, а не выполнять вычисления.
Повторим наш запрос для отчета из предыдущего раздела, но в ленивом режиме:
lazy_report_query = (
lazy_df_sales # Начинаем с LazyFrame
.filter(
(pl.col("sku_category").is_in(["Категория А", "Категория Б"])) &
(pl.col("order_month") == 3)
)
.group_by("customer_name", "sku_category")
.agg(
pl.sum("total_price").alias("total_value"),
pl.sum("quantity").alias("total_quantity")
)
.sort("customer_name", "sku_category")
)
print("\nТип объекта запроса:")
print(type(lazy_report_query))
# <class 'polars.lazyframe.frame.LazyFrame'>
print("\nСам объект запроса (всё ещё ленивый):")
print(lazy_report_query)
# naive plan: (run LazyFrame.explain(optimized=True) to see the optimized plan)lazy_report_query — это всё еще LazyFrame. Мы описали что мы хотим сделать, но никаких вычислений ещё не произошло.
Заглянем под капот
Как посмотреть, что Polars собирается делать? Метод .explain() показывает оптимизированный план запроса в текстовом виде. Читать его нужно снизу вверх.
print("\nОптимизированный план запроса (текст):")
print(lazy_report_query.explain())Оптимизированный план запроса (текст):
SORT BY [col("customer_name"), col("sku_category")]
AGGREGATE
[col("total_price").sum().alias("total_value"), col("quantity").sum().alias("total_quantity")] BY [col("customer_name"), col("sku_category")]
FROM
FILTER [(col("sku_category").is_in([Series])) & ([(col("order_month")) == (3)])]
FROM
DF ["order_id", "customer_name", "product_sku", "quantity", ...]; PROJECT["total_price", "quantity", "customer_name", "sku_category", ...] 5/10 COLUMNSЗдесь видно, что Polars сначала применяет FILTER к исходному датафрейму, затем выбирает (PROJECT) только нужные для агрегации столбцы, выполняет саму агрегацию (AGGREGATE) и, наконец, сортирует (SORT).
Выполнение запроса
Чтобы наконец выполнить оптимизированный план запроса и получить результат в виде обычного (жадного) датафрейма, используется метод .collect():
# Выполняем ленивый запрос
report_final = lazy_report_query.collect()
print("\nТип результата после .collect():")
print(type(report_final))
# <class 'polars.dataframe.frame.DataFrame'>
print("\nИтоговый DataFrame:")
display(report_final)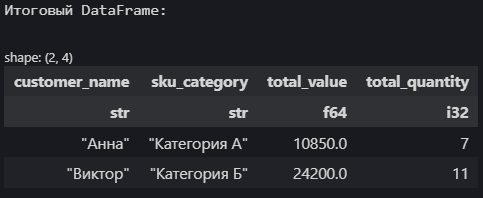
Только в момент вызова .collect() Polars выполняет все шаги оптимизированного плана и возвращает вам результат — обычный датафрейм, с которым можно работать дальше или сохранить его.
Хотя для простых операций или интерактивного исследования жадный API может быть удобнее, для сложных цепочек преобразований и работы с большими объемами данных стоит всегда рассматривать использование Lazy API.
Сканирование больших данных
Стандартные функции чтения вроде pl.read_csv() или pl.read_parquet() удобны, но у них есть фундаментальное ограничение: они пытаются загрузить весь файл в оперативную память сразу. Если ваш CSV-файл весит 10 ГБ, а у вас всего 8 ГБ ОЗУ (или даже 16 ГБ, но они уже заняты другими процессами), то мы, скорее всего, столкнёмся с ошибкой MemoryError или система начнет невыносимо тормозить из-за использования файла подкачки.
Именно здесь на помощь приходит Lazy API в сочетании со специальными функциями сканирования: pl.scan_csv(), pl.scan_parquet(), pl.scan_ipc() (для формата Arrow/Feather) и другими.
Вместо того чтобы читать весь файл, функции scan_* делают следующее:
- Быстро сканируют метаданные файла. Они определяют схему данных (имена столбцов и их типы), не загружая сами данные.
- Создают LazyFrame. Возвращается не обычный DataFrame, а LazyFrame, который "указывает" на файл на диске.
- Отложенное чтение. Сами данные из файла будут считываться только в момент вызова
.collect()на этом LazyFrame (или при записи результата в другой файл). Причем благодаря оптимизатору запросов Polars будет стараться читать только те части файла и те столбцы, которые действительно необходимы для выполнения запроса, и обрабатывать их поблочно (чанками).
Давайте используем известный открытый набор данных — поездки такси Нью-Йорка. Мы возьмем данные за январь 2024 года в формате Parquet. Этот файл содержит почти 3 миллиона записей (около 50 МБ в сжатом Parquet, но гораздо больше в памяти)., не так много, но для демонстрации преимуществ Polars вполне достаточно. И мы сразу воспользуемся одной из ключевых возможностей библиотеки — ленивым сканированием. Вместо того чтобы загружать весь файл в оперативную память сразу, мы используем функцию pl.scan_parquet().
import polars as pl
url = "https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2024-01.parquet"
# Создаем LazyFrame, читая только метаданные Parquet файла по URL.
lazy_taxi_data = pl.scan_parquet(url)
# Определяем агрегацию: средняя длительность и сумма поездки
# для поездок с > 1 пассажиром, сгруппировав по зоне посадки.
lazy_query = (
lazy_taxi_data
.filter(pl.col("passenger_count") > 1)
.group_by("PULocationID")
.agg(
(pl.col("tpep_dropoff_datetime") - pl.col("tpep_pickup_datetime"))
.mean()
.dt.total_seconds()
.alias("avg_duration_seconds"),
pl.mean("total_amount").alias("avg_total_amount"),
pl.len().alias("num_trips")
)
.filter(pl.col("num_trips") > 100)
.sort("num_trips", descending=True)
)
# Polars скачивает данные по частям с URL, выполняет фильтры,
# агрегации и возвращает итоговый DataFrame.
final_report = lazy_query.collect() # Запрос выполняется здесь
# Результат - обычный датафрейм
print("\nИтоговый отчет (первые 5 строк):")
display(final_report.head())
Здесь чтение данных происходит по требованию во время .collect(), что позволяет обрабатывать файлы, значительно превышающие объем доступной ОЗУ.
Работа с разными форматами и интеграция с Pandas
Мы уже видели pl.scan_csv() и pl.scan_parquet(). Polars поддерживает чтение и запись множества других форматов.
- "Жадное" чтение. Функции
pl.read_*(например,pl.read_csv,pl.read_parquet,pl.read_json,pl.read_excel,pl.read_sql) загружают данные полностью в память, возвращая обычный датафрейм. Это удобно для небольших файлов или когда ленивость не нужна. - Ленивое сканирование. Функции
pl.scan_*(например,pl.scan_csv,pl.scan_parquet,pl.scan_ipc) **не загружают** данные, а возвращаютLazyFrame. Это предпочтительный способ для больших файлов, как мы видели в предыдущем разделе. - Запись данных. Методы
.write_*у DataFrame и LazyFrame (.sink_*) позволяют сохранять данные в различные форматы.
import pandas as pd
import numpy as np
# Создадим небольшой DataFrame для демонстрации записи
# (В реальном коде здесь мог бы быть результат предыдущих шагов, как final_report)
write_example_df = pl.DataFrame({
"PULocationID": [1, 2, 3],
"avg_duration_seconds": [600.5, 750.2, 800.0],
"avg_total_amount": [25.5, 30.0, 35.8],
"num_trips": [150, 200, 120]
})
print("--- Примеры записи данных ---")
print("Используем DataFrame:")
print(write_example_df)
# --- Запись данных ---
csv_path = "report_example.csv"
write_example_df.write_csv(csv_path)
print(f"\nСохранено в CSV: {csv_path}")
parquet_path = "report_example.parquet"
write_example_df.write_parquet(parquet_path)
print(f"Сохранено в Parquet: {parquet_path}")
json_path = "report_example.ndjson"
write_example_df.write_ndjson(json_path)
print(f"Сохранено в JSON Lines: {json_path}")
# Запись в Excel (требует установки xlsxwriter: pip install xlsxwriter)
excel_path = "report_example.xlsx"
write_example_df.write_excel(
excel_path,
table_style="Table Style Medium 2",
autofit=True
)
print(f"Сохранено в Excel: {excel_path}")
# --- Чтение данных (жадное) ---
print("\n--- Примеры чтения данных ---")
df_from_csv = pl.read_csv(csv_path)
print(f"\nПрочитано из CSV ({df_from_csv.shape}):\n{df_from_csv.head(3)}")
df_from_parquet = pl.read_parquet(parquet_path)
print(f"\nПрочитано из Parquet ({df_from_parquet.shape}):\n{df_from_parquet.head(3)}")
df_from_json = pl.read_ndjson(json_path)
print(f"\nПрочитано из JSON Lines ({df_from_json.shape}):\n{df_from_json.head(3)}")
# --- Ленивое сканирование Parquet файла ---
print("\n--- Пример ленивого сканирования Parquet файла ---")
lazy_df = pl.scan_parquet(parquet_path)
print(f"Создан LazyFrame из {parquet_path}")
print(f"Результат collect():\n{lazy_df.collect().head(3)}")Также Polars обеспечивает эффективную конвертацию данных в/из Pandas DataFrame и NumPy массивов, часто без копирования данных, благодаря использованию Apache Arrow.
# Используем DataFrame из предыдущего примера чтения
polars_df_to_convert = df_from_parquet
# --- Polars -> Pandas ---
df_pandas = polars_df_to_convert.to_pandas()
# --- Polars -> NumPy ---
numpy_array = polars_df_to_convert.to_numpy()
# --- Pandas -> Polars ---
pandas_example = pd.DataFrame({
'col_a': [10, 20, 30],
'col_b': ['x', 'y', 'z']
})
print(pandas_example)
df_polars_from_pandas = pl.from_pandas(pandas_example)
# --- NumPy -> Polars ---
numpy_example = np.array([[1.1, 2.2], [3.3, 4.4], [5.5, 6.6]])
print(numpy_example)
# ВАЖНО: При конвертации из NumPy нужно указать схему (имена и типы)
df_polars_from_numpy = pl.from_numpy(
numpy_example,
schema={"val1": pl.Float64, "val2": pl.Float64}
)Это позволяет постепенно внедрять Polars в свои проекты: например, можно использовать его для выполнения "тяжелых" операций над данными, а затем вернуть результат в Pandas для дальнейшей работы с другими библиотеками экосистемы (хотя все больше библиотек начинают поддерживать Polars напрямую через Arrow).
Polars vs Pandas: когда что выбрать?
Отлично, мы подошли к важному вопросу: раз Polars такой быстрый и эффективный, значит ли это, что пора полностью отказаться от Pandas? Не совсем. Выбор инструмента зависит от конкретной задачи и ваших приоритетов. Давайте разберемся, когда каждый из них сияет ярче.
- Критична производительность и работа с большими данными: Это главная сила Polars. Если ваши данные измеряются гигабайтами (или даже терабайтами!), если операции Pandas выполняются мучительно долго или приводят к ошибкам нехватки памяти (MemoryError), Polars — ваш основной кандидат. Его ядро на Rust, использование Arrow, встроенный параллелизм и ленивые вычисления дают существенное преимущество.
- Необходимость максимальной утилизации CPU: Polars спроектирован для автоматического распараллеливания вычислений на все доступные ядра процессора без дополнительных усилий со стороны пользователя. Если вы хотите выжать максимум из своего "железа", Polars поможет.
- Сложные цепочки операций: Lazy API Polars позволяет оптимизировать всю последовательность преобразований целиком. Если вы часто строите длинные цепочки .filter().with_columns().group_by().agg()..., ленивый подход Polars может дать значительный прирост скорости и сэкономить много памяти по сравнению с "жадным" выполнением в Pandas.
- Работа с данными, превышающими ОЗУ (Out-of-Core): Благодаря ленивому сканированию (scan_*) и обработке по частям, Polars может эффективно обрабатывать датасеты, которые физически не помещаются в оперативную память.
- Предпочтение консистентного API и отсутствия индексов: Некоторым пользователям API Polars кажется более строгим, последовательным и предсказуемым, чем API Pandas с его особенностями (например, поведение методов inplace, возвращение копии vs представления). Отсутствие концепции индекса в стиле Pandas также может упростить некоторые операции для тех, кто не полагается на специфические функции индексации.
- Начало нового проекта с фокусом на производительность: Если вы начинаете проект с нуля и ожидаете работы с большими объемами данных, заложить использование Polars с самого начала может быть стратегически верным решением.
Когда Pandas может быть предпочтительнее (или пока незаменим):
- Огромная экосистема и интеграции: Pandas существует гораздо дольше, и вокруг него выросла гигантская экосистема. Множество библиотек для статистики, машинного обучения, визуализации и других специфических задач изначально создавались с расчетом на Pandas DataFrame как основной формат входных данных. Хотя ситуация быстро меняется (многие библиотеки добавляют поддержку Polars через Arrow), для некоторых узкоспециализированных инструментов интеграция с Pandas все еще может быть более гладкой.
- Зрелость, стабильность и огромное сообщество: Код Pandas проверен временем и используется в бесчисленном количестве проектов. Если вам нужна максимальная стабильность или вы часто ищете решения конкретных проблем на Stack Overflow, обширное сообщество и накопленная база знаний Pandas могут быть большим плюсом.
- Активное использование мульти-индексов и специфических функций индексации: Если ваша работа сильно завязана на использовании сложных мульти-индексов Pandas, операциях stack()/unstack() или продвинутых техниках индексации, которых нет в Polars (так как у него другая философия работы со строками и столбцами), переход может потребовать значительного переосмысления кода.
- Работа с небольшими и средними данными: Если ваши датасеты относительно невелики (сотни мегабайт или меньше), и Pandas справляется с ними достаточно быстро, выигрыш в производительности от перехода на Polars может быть не столь значительным, чтобы оправдать время на изучение нового API.
- Простая встроенная визуализация: Pandas имеет удобную интеграцию с Matplotlib через метод .plot(), позволяя быстро строить базовые графики прямо из DataFrame. В Polars встроенных средств визуализации нет (хотя его легко использовать с основными библиотеками визуализации через .to_pandas() или напрямую, если библиотека поддерживает Arrow).
Polars и Pandas — не столько конкуренты, сколько инструменты с разными сильными сторонами. Polars — это высокопроизводительная альтернатива, идеально подходящая для ресурсоемких задач и больших данных. Pandas — это зрелый, универсальный инструмент с огромной экосистемой.
Лучший подход часто заключается в том, чтобы знать оба инструмента и использовать тот, который лучше подходит для конкретной задачи. Благодаря легкой конвертации между ними, вы даже можете использовать Polars для "тяжелых" вычислений, а затем вернуть результат в Pandas для дальнейшей работы с другими библиотеками.
Заключение
Итак, мы совершили погружение в мир Polars — библиотеки, которая уверенно заявляет о себе как о серьезной альтернативе или дополнении к привычному Pandas.
- Polars быстр. Очень быстр. Благодаря ядру на Rust, использованию Apache Arrow и встроенному параллелизму, он способен обрабатывать большие объемы данных значительно эффективнее, чем традиционные инструменты.
- Lazy API — это мощь. Ленивые вычисления позволяют Polars оптимизировать ваши запросы "под капотом", экономя память и время выполнения, особенно в сложных цепочках операций.
- Работа с большими файлами — не проблема. Функции scan_* в сочетании с Lazy API открывают возможность анализировать данные, которые просто не поместятся в вашу оперативную память.
- API — строгий, но логичный. Polars предлагает консистентный интерфейс и уделяет внимание типам данных, что способствует надежности и производительности.
- Интеграция — на уровне. Polars легко обменивается данными с Pandas и NumPy, позволяя встроить его в существующие рабочие процессы.
Я бы сказал, что Polars и Pandas — не столько конкуренты, сколько инструменты с разными сильными сторонами. Polars — это высокопроизводительная альтернатива, идеально подходящая для ресурсоемких задач и больших данных. Pandas — это зрелый, универсальный инструмент с огромной экосистемой.
Лучший подход часто заключается в том, чтобы знать оба инструмента и использовать тот, который лучше подходит для конкретной задачи. Благодаря легкой конвертации между ними, вы даже можете использовать Polars для "тяжелых" вычислений, а затем вернуть результат в Pandas для дальнейшей работы с другими библиотеками.
Разнообразие инструментов и подходов всегда полезно 😊