How to Establish an Amazon Redshift Connection in DataStage
Amazon Redshift is a data warehouse, which allows us to connect through standard SQL based clients and business intelligence tools effectively. It delivers fast query performance by using row-wise data storage by executing the queries parallel in a cluster on multiple nodes.

Pre-requisites:
- IBM InfoSphere DataStage Quality Stage Designer — v 9.1.0
- Create an account in AWS and configure Redshift DB, refer to this link to configure
- Download AWS Redshift DB Driver
If you want to Gain In-depth Knowledge on DataStage, please go through this link DataStage Training
Step-by-Step process:
Step 1: To connect AWS Redshift Database in Datastage, use the JDBC Connector which is available under the Database section in the palette.
- Create a new file and name it as config file under $DSHOME (/opt/IBM/InformationServer/Server/DSEngine) path.
Note: If we had already connected any database using JDBC connector, then the file would be existing already. We need to edit the existing file in this case.

- Add the downloaded AWS Redshift DB Driver (RedshiftJDBC4–1.2.1.1001.jar) file in any path and mention that file’s path in CLASSPATH parameter. In CLASS_NAMES parameter, we need to mention the class name, which is available in the jar file.
Note: If we want to add more jar files or more class names, the jar file paths or class names should be separated by a semicolon (;)

- The below screenshot will show that the downloaded jar file is placed in the path mentioned in isjdbc.config

Step 2: Develop a Datastage job by having a JDBC connector (available under Database section in palette) as the source or Target datastage administrator training helps you to learn more techniques and skills more effectively.
- Create a new parallel job with the JDBC Connector as source.
- Open the JDBC connector and fill the JDBC URL in the URL section and fill the User name/password & Table name like below,
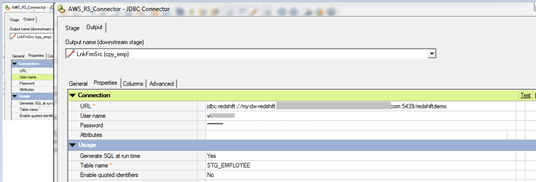
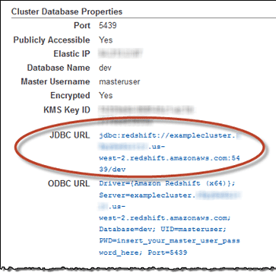
3. The JDBC URL will be available in the Cluster Database Properties in the AWS console. The JDBC URL will be like below,
- jdbc:redshift://<ServerName>:<Port>/<Database Name>
- Server Name: It will differ for every individual connection
- Port number: 5439 (Common for all Redshift DB)
- Database Name: redshiftdemo (I have created during the configuration)
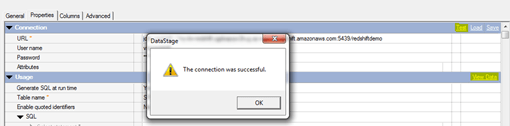
- Once the parameters are filled in the JDBC Connector, test the connection like below
Note: Check whether the AWS Redshift is running or not, before testing the connection
- We can view the data in datastage, once we establish our connection successfully
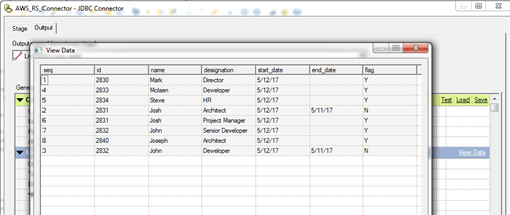
Step 3: Now the connection is established successfully and we can develop our job with the stages needed. Below, I’ve created a simple mapping with copy stage and sequential file as our target. The below job is successfully completed and 8 records from the source are exported and the same number of records have been loaded into the sequential file
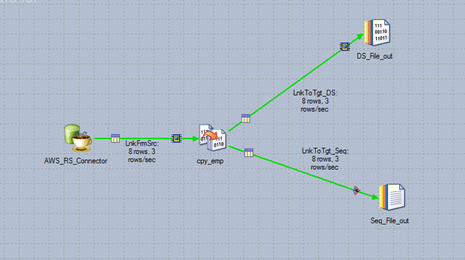
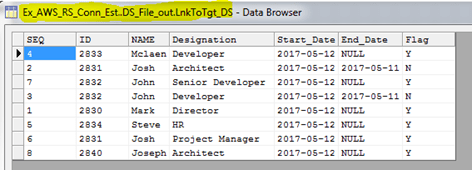
Step 4: Check the target to see if the records are loadeded successfuly or not like below,
Troubleshooting:
- java.lang.UnsupportedClassVersionError: bad major version at offset=6 –
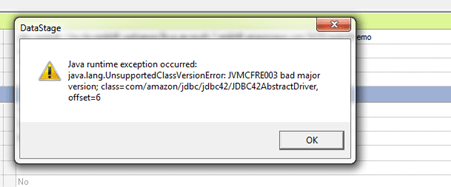
Cause: The version which is used to compile the jar file is different from jre which is available in your Unix machine
Solution: Use lower version of the jar file or compile with same java runtime environment
- The driver configuration file isjdbc.config could not be found –
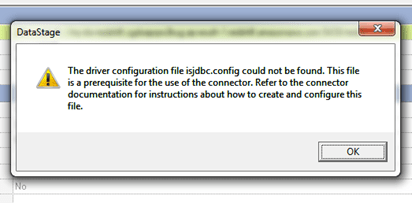
Cause: This will happen if we don’t place the isjdbc.config file in $DSHOME path
Solution: We have to place the isjdbc.config file in $DSHOME path (/opt/IBM/InformationServer/Server/DSEngine). Datastage administrator training from industrial experts.