Сводная информация по параметрам
ДАННАЯ ИНФОРМАЦИЯ СИЛЬНО УСТАРЕЛА НЕ АКТУАЛЬНА! ОНА БЫЛА НАПИСАНА В 2022 ГОДУ!
Первое поле «Promt» — буквально означает «подсказка». Это текстовое описание, того, что должна сгенерировать сеть. Чем подробнее будет запрос — тем точнее результат. Прочти о составлении промптов.
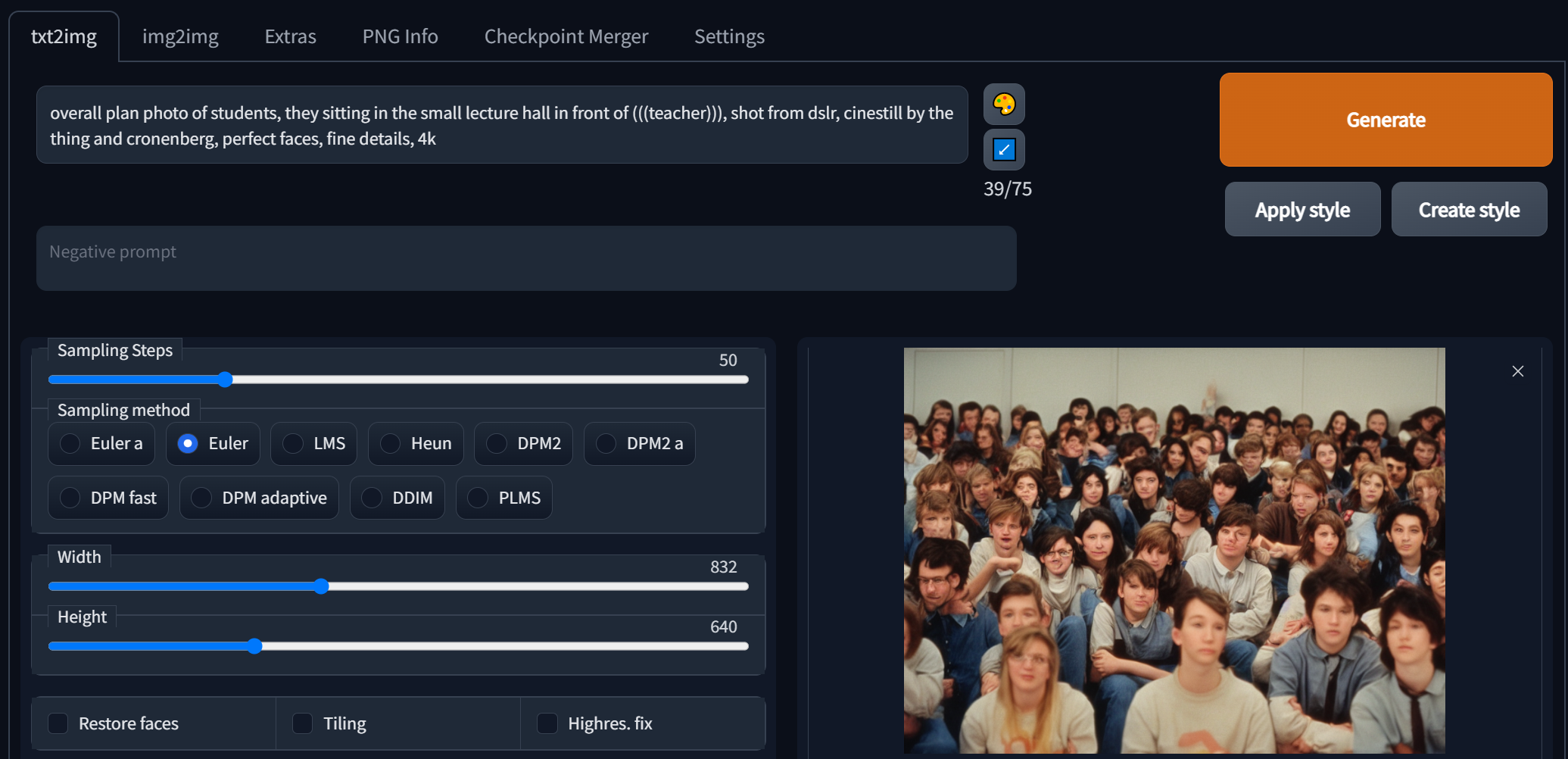
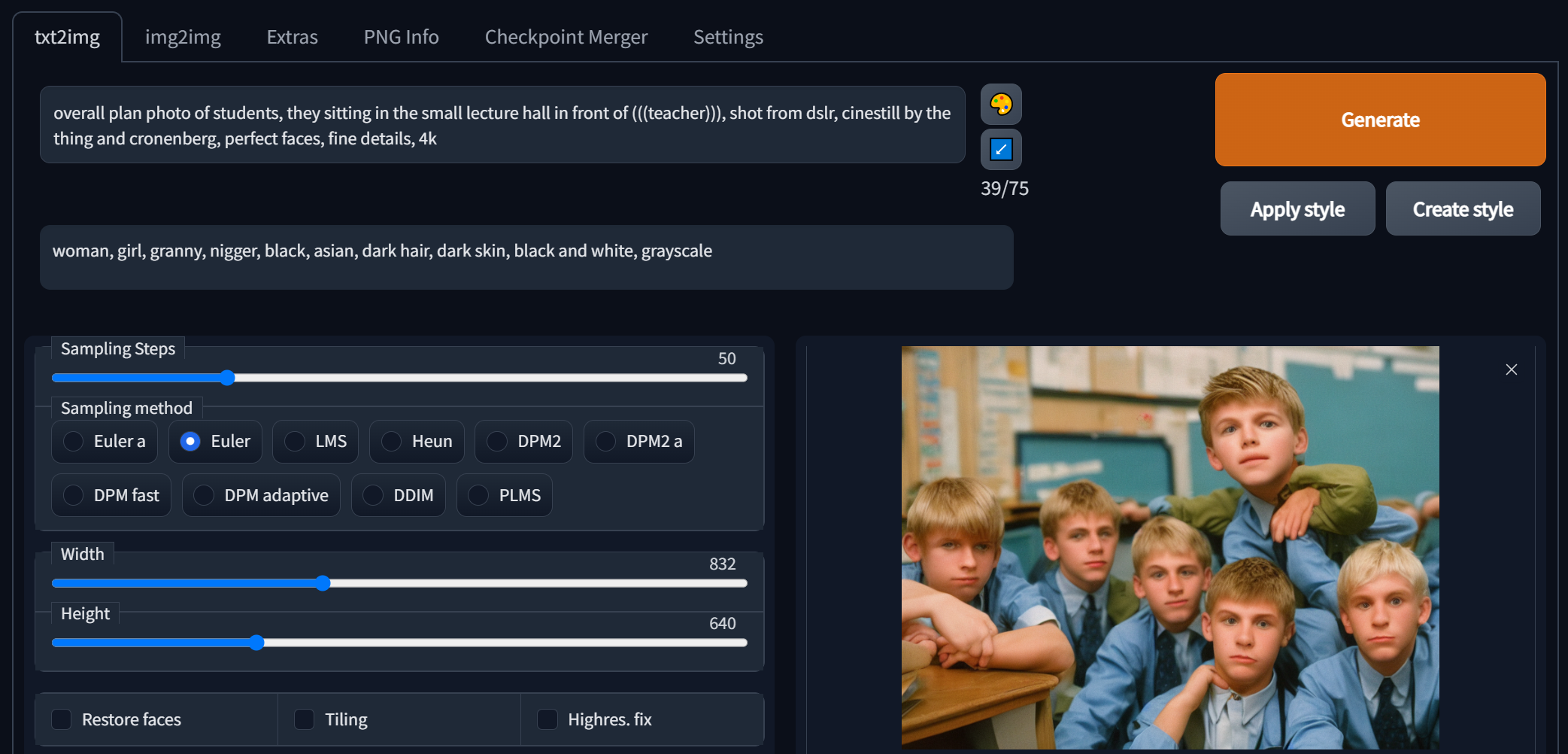
Второе поле «Negative prompt» — это все то, что мы не хотим видеть на картинке. Например, мы генерируем «студенты сидят в лектории перед преподавателем», и, естественно, не хотим чтобы там были женщины. Поэтому в поле негативного промпта мы напишем: женщина, девочка, феминность, старуха, женственность. Сюда же вписываются такие токены как например «черно-белое, оттенки серого, негры, азиаты, темный цвет волос, темная кожа».
Сравни до и после применения негативных промптов:
Стили
Под кнопкой генерации есть еще кнопки управления стилями:
Они позволяют сохранить твои промпты в качестве заготовок или стилей, чтобы их можно было использовать потом. Свои сохраненные стили можно еще и комбинировать из двух.
- Кнопка «Apply style» вставляет текст стиля в поле промпта.
- Если добавить в текст стиля токен {prompt}, это позволит обернуть слово или фразу из поля ввода «внутрь» текста стиля. Пример:
full body portait of {prompt}, painting by Tom of Finland. - Все стили хранятся в styles.csv в корневой папке, в виде синтаксиса:
name,«prompt»,«negative_prompt». Стили можно редактировать, удалять и добавлять новые прямо в этом файле.
А рядом с полями ввода промпта есть небольшая кнопка палитры 🎨 для случайно подстановки художников, чей стиль нужно повторить для запроса.
Сэмплеры и шаги семплирования
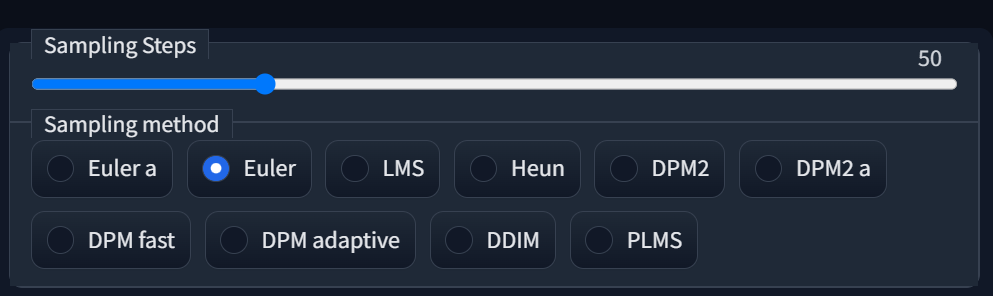
Sampling steps — количество итераций, или шагов, необходимых нейросети для обработки запроса. Больше шагов — более долгая генерация, и теоретически — более детальное изображение (что во все не означает, что нужно всегда ставить на 100-200 шагов). Для разных методов выборки (сэмплеров), существует оптимальная граница, после которой дальнейшее увеличения числа шагов либо не имеет смысла, либо только ухудшит результат. Например для Euler a оптимальным считается диапазон 20-35 шагов, для LMS - в районе 50.
Sampling methods или сэмплеры — различные математические функции, по которым генерируется шум для преобразования его в изображение.
Ведь принцип диффузионной модели нейросети в том и заключается, что сначала генерируется случайный шум, и из него «восстанавливается изображение»:
Сравнение различных сэмплеров, при генерации одной и той же картинки
По идее, сэмплер нужно опытным путем подбирать под конкретный запрос, чтобы выискать наиболее лучший результат. Но, в большинстве случаев достаточно использовать сэмплер Euler-a либо LMS.
Пропорции и размеры изображения
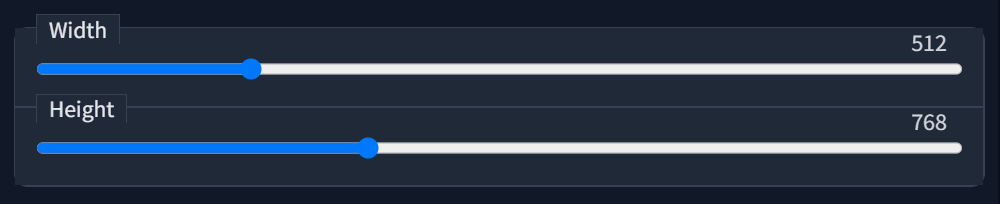
Ползунками настраиваем желаемый размер и пропорции будущих картинок. Базовые размеры - это квадрат на 512 пикселей. Предсказуемые результаты возможны только при таком размере, поскольку стандартную модель обучали именно на квадратных картинках 512x512px. При увеличении разрешения нейросеть может начать дублировать его части, от чего появляются лишние головы, конечности и персонажи. Тем не менее, порой можно получить приличный результат и при «нестандартном» разрешении. Тем более, в интерфейсе есть галочка, помогающая бороться с этим недостатком, об этом чуть позже.
Пропорции лучше подбирать исходя из типа изображения: для группового фото или пейзажа нужен горизонтальный прямоугольник, для дальних сцен общего плана - широкий формат, для портретов - вертикальный прямоугольник 4:5, для ростового портрета всего тела - еще более вытянутый 2:3 и так далее.
Исправление лиц, паттерны, фикс для высокого разрешения

Тут можно отметить галочки, чтобы изменить способ обработки и выполнить постобработку.
- Resore face — исправляет искаженные лица и артефакты на них. Используется две дополнительные нейросети: GFPGAN или CodeFormer. Какая лицевая нейросеть будет использоваться и с какой силой будет выполнятся «исправление» — выбирается в общих настройках, на вкладке Settings в webUI. Как правило, самый качественный результат дает CodeFormer, но он делает лица очень фотореалистичными, что может не всегда быть к месту. Надо еще отметить, что лицевые нейросети на самом деле ничего не восстанавливают, а создают абсолютно новые лица, порой не имеющие ничего общего с исходным.
- Tiling - это специальный режим генерации, полезный для дизайнеров, разработчиков игр, и всех тех, кому нужны бесшовные текстуры и паттерны. Именно с этой галочкой вместо обычных картинок будут генерироваться вот такие штуки:

3. Highres. fix - исправляет артефакты, свойственные при генерации в высоком разрешении или нестандартном соотношении сторон(все что не квадрат). Нейросеть сперва генерирует маленькое изображение, а потом на его основе создается большое, с добавлением деталей.

Пакетная генерация
Иногда может понадобиться создать много картинок по одному промпту, например чтобы потом из сотен изображений отобрать наиболее удачные. Для этого существует пакетная генерация нескольких изображений:

Batch count — сколько сгенерировать картинок последовательно, а Batch size — сколько параллельно. Параллельная генерация требует больших ресурсов видеокарты в плане VRAM, и этот ползунок лучше не трогать, если железо не позволяет.
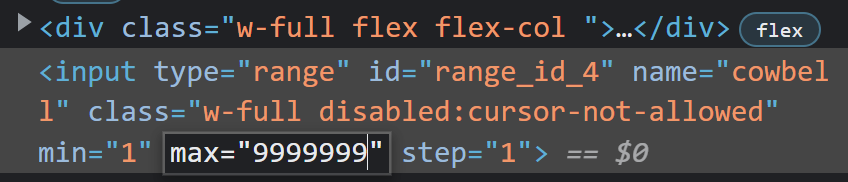
Если количество картинок, предлагаемое ползунком тебя не устраивает, есть лайфхак, как его изменить прямо в браузере, не редактируя файлы настроек, очень просто кликнуть правой кнопкой мыши по ползунку и выбрать «Просмотреть код», после чего поменять параметр max по своему вкусу:
CFG Scale
Classifier-free Guidance Scale (CFG Scale) — шкала безклассификаторного управления уровнем диффузии. Указывает нейросети, как сильно изображение должно соответствовать каждому токену запроса. Чем меньше значение — тем больше нейросеть «фантазирует», чем оно больше — тем точнее и детальнее получаются картинки. Слишком низкие значения приведут к генерации рандома, а слишком высокие — приведут к искаженным изображениям, с вырвиглазным контрастом и цветами. В основном, оптимально использовать средние значения в диапазоне 5-14. По умолчанию — 7. Ни в коем случае не выкручивай этот параметр более 12, если не понимаешь что делаешь.

CFG Scale может быть равно 0 и принимать отрицательные значения - в этих случаях нейросеть будет генерировать вообще случайные изображения. Как видно из таблицы выше, использовать значения меньше 3 и выше 20 смысла не имеет. Более высокие значения могут быть задействованы при большом количестве шагов сэмплирования и определенных сэмплерах.
Сид, зерно, начальное/отправное значение

Seed — число, из которого генерируется шум. Если указать -1, сид будет рандомный во всех генерациях (кнопочка 🎲). Кнопочка ♻️ вызывает последний использовавшийся сид.
Extra открывает дополнительные настройки:
Variation seed и Variation strength позволяют интерполировать шум между двумя сидами. Таким образом мы можем получить что-то среднее между двумя картинками. С ancestral-сэмплерами (которые с суффиксом а) эта опция работает иначе и выдает совершенно разные новые картинки, чем были с исходным сидом, потому использовать эту опцию с такими сэмплерами, пожалуй, мало смысла, из-за полной непредсказуемости результата.
Пользоваться очень просто: в Seed вставляем сид исходной картинки, в Variation seed — сид другой картики, которую мы генерировали с этим же промптом и настройками. Ползунком Variation strength регулируется степень смешивания сидов, а значит и двух картинок между собой, например 0,5 будет означать смешивание 50/50.
Resize seed — создает из картинки похожую, с изменением размеров.

К сожалению, когда меняется размер картинки, при сохранении всех прежних параметров и сида, то на выходе получается просто совершенно иное изображение. Чтобы попытаться избавиться от этой проблемы и существует опция Resize seed — нейросеть будет стараться сделать картинку с новым разрешением, максимально похожую на оригинал.
Использовать просто: фиксируем сид нужной картинки кнопкой ♻️, или вводим вручную, меняем в параметрах генерации разрешение Width и Height, активируем галочку Extra, в параметрах Resize seed ползунками Resize seed from width и Resize seed from height указываем изначальное разрешение картинки. Теперь сгенерируется картинка, в новом разрешении, и она будет уже не рандомная, а очень похожая на исходник. Нужно иметь в виду, что эта фича не работает с ancestral-сэмплерами (которые с суффиксом а).
Таблички показывающие как разные семплеры и количество итераций влияет на результат
(в полном размере открывайте по правому клику в новом окне)


Сэмплерами и количествами шагов на примере копродедов