Современные алгоритмы обработки данных(Часть 2)

Алгоритм решения задач оптимизации, основанный на идеях наследственности в биологических популяциях, был впервые предложен Джоном Холландом (1975). Он получил название репродуктивного плана Холланда, и широко использовался как базовый алгоритм в эволюционных вычислениях.
Современные алгоритмы обработки данных
Современные алгоритмы обработки данных
Графы
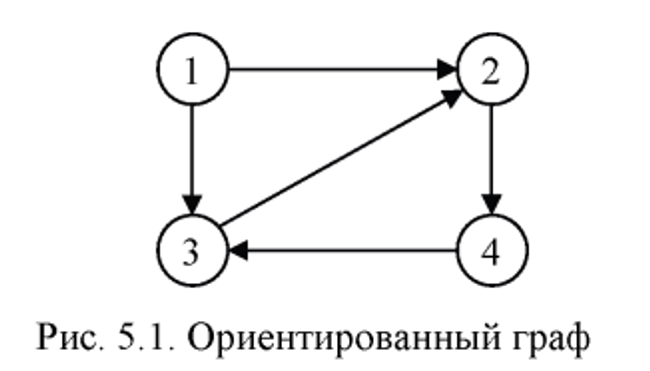
Граф - это математическая абстракция реальной системы любой природы, объекты которой обладают парными связями. Граф, как математический объект, есть совокупность двух множеств. Множества вершин и множества ребер (парных связей/дуги).
Хеширование данных

Хэш таблица представляет собой эффективную структуру данных для реализации словарей. Хотя на поиск элемента в хэш таблице в наихудшем случае может потребоваться столько же времени что и в связанном списке О(n) на практике хеширование является намного эффективнее. Три вполне обоснованных допущениях математическое ожидания времени поиска элемента хэш таблицы составляют О(1).
АВЛ Деревья
АВЛ-дерево - это структура данных, придуманная в 1962 году советскими учеными. Это модификация классического бинарного дерева поиска, благодаря которой структура лучше сбалансирована и практически не может выродиться. Вырождение - это ситуация, когда у каждого узла оказывается только по одному потомку, и структура становится линейной (не оптимальной). Благодаря сбалансированности и почти невозможности вырождения дерева, информация хранится более эффективно, поэтому доступ к данным оказывается быстрее, и найти становится легче.
Деревья
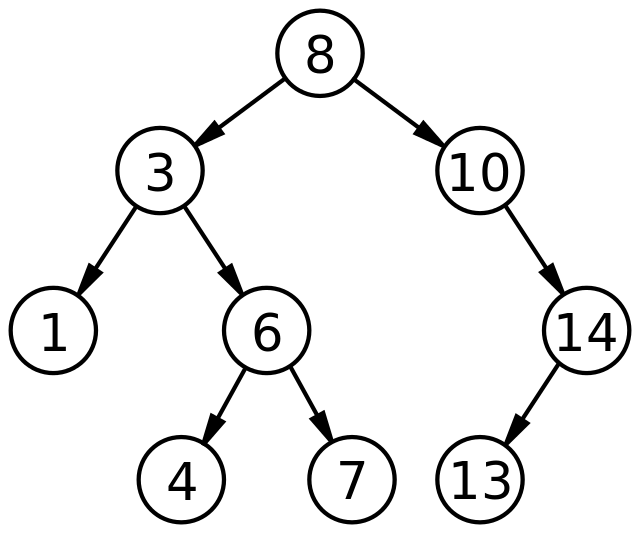
Бинарные деревья поиска - это структура данных, которая позволяет хранить элементы в отсортированном порядке для эффективного поиска, вставки и удаления. Основные операции выполняются за время, пропорциональное глубине дерева. Для полного дерева с n узлами эти операции выполняются за O(logn). Бинарные деревья поиска также поддерживают запросы на поиск минимального и максимального элементов, предшествующего и последующего элементов.
Алгоритмы сортировки(2 часть)

Сортировка Шелла является улучшенным методом, основанном на методе прямого включения с уменьшающимися расстояниями.
Алгоритмы сортировки
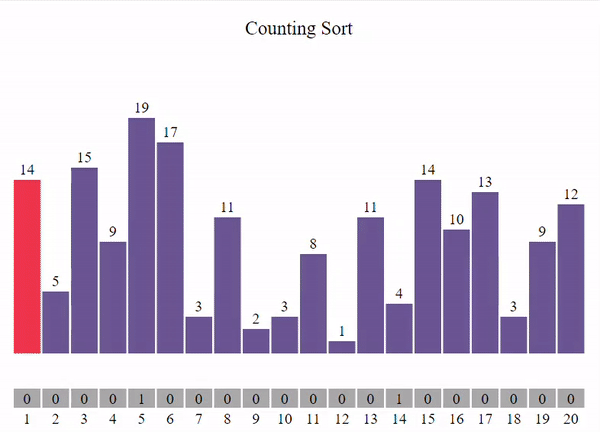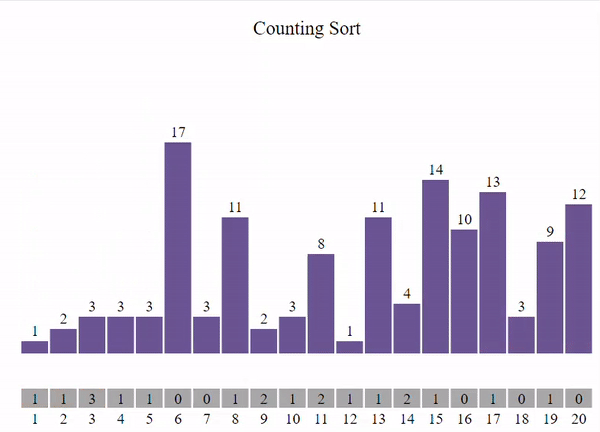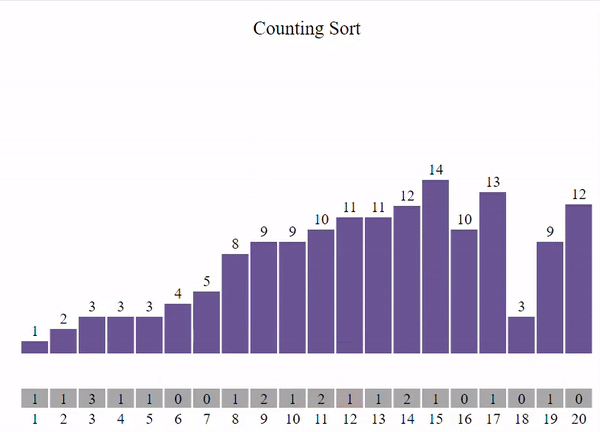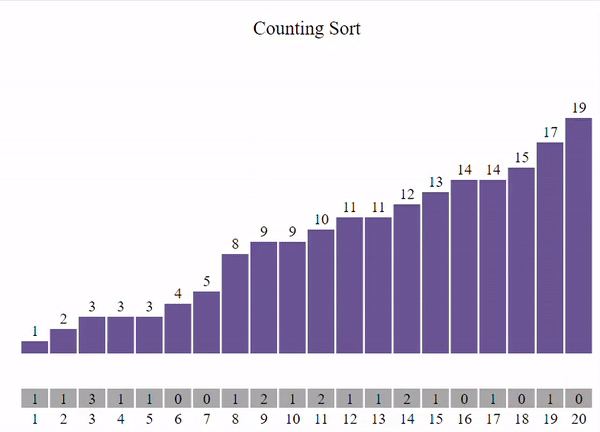
В общем виде задачу сортировки можно сформулировать следующим образом: Имеется последовательность однотипных записей, одно из полей которых выбрано в качестве ключевого(ключ сортировки). Тип данных ключа должен включать операции сравнения.
Алгоритмы поиска(2 часть)
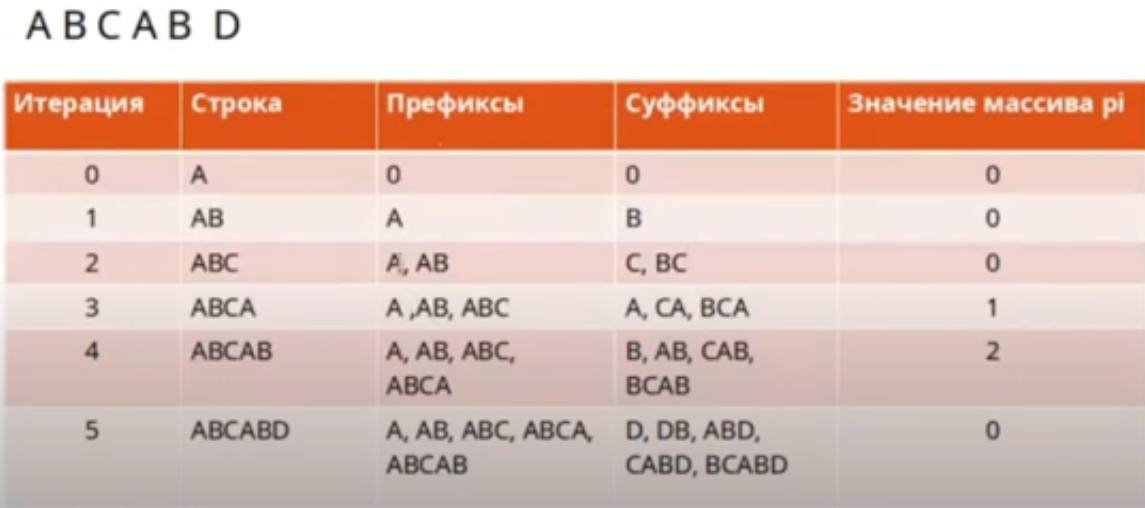
Алгоритм Кнутта-Морриса-Пратта (KMP) - это алгоритм поиска подстроки, который использует принцип сдвига образа для ускорения поиска. Он состоит из двух этапов: