What is ZEXE?

Introduction
Distributed ledger systems have become popular since the advent of cryptocurrencies. A typical distributed ledger scheme is built on blockchain technology, which is distinguished by a special data structure that stores information about transactions in the form of blocks. These blocks of data are “linked” or linked together by a cryptographically calculated number called a hash, and this hash uniquely identifies a given block.
Despite their growing popularity, distributed ledger system schemes typically provide only limited privacy. In addition, privacy schemes tend to be limited in their expressiveness in terms of the programs they support.
It is this problem that prompted privacy researchers (including several of the founding scientists of ZCash) to develop a scheme they called ZEXE, or Zero-knowledge EXEcution. ZEXE is the first ledger-based scheme where applications can run publicly, privately and scalably.
While Aleo was founded by several ZEXE contributors and these studies are a key part of its computational model, Aleo is more than just ZEXE. It goes beyond providing a full-stack approach for writing private applications.
However, ZEXE is the main component of Aleo. However, it remains relatively unknown outside of research circles. Therefore, the purpose of this series of articles is to provide additional context for the ZEXE development strategy, to talk about what it allows, and to describe the real applications that can be built with it.
Preliminary information
In order to appreciate the design of ZEXE, it is very important to first understand a little more about what cryptocurrencies have under the hood. So first we’ll start with additional context and explain the basic cryptographic primitives that make ZEXE possible.
So, in the next section, we will discuss some key concepts regarding the privacy of cryptocurrencies, as well as two cryptographic primitives that are a key part of ZEXE and other privacy models: commitment schemes and zero-knowledge proofs.
Data privacy and feature privacy
In cryptocurrencies, a transaction is a record of some exchange of value in the form of digital assets from one wallet address to another. For example, a Bitcoin transaction consists of three parts: input, output, and the amount sent, although the amount is actually reflected as part of the output.
So, if Bob sends 50 BTC to Alice, then
- the inputs are the BTC address from which Bob originally received the 50 BTC, the hash of the previous transaction, and the signature of the person who signed those coins to Bob
- the amount — is the 50 BTC that Bob sends.
- the output often includes the above amount, Alice’s address, the hash of the current transaction, and Bob’s signature.
Anyone viewing the Bitcoin ledger can see this transaction information. Although the names of Bitcoin owners are not explicitly recorded, it would not be difficult for a determined attacker with modest computing power to associate addresses with real owners over time. For this reason, Bitcoin is pseudonymous and provides no real privacy.
To solve this problem, private cryptocurrencies like Monero use hidden addresses. That is, for each transaction, coin sender A selects a random one-time address for recipient B. By using stealth addresses, only the sender and recipient can determine where the payment was sent. This is one way to provide more privacy than Bitcoin.
Account-based systems like Ethereum have even worse privacy properties because each public key is reused as an address. However, Ethereum provides additional programmability that is largely lacking in other privacy schemes.
Commitment schemes
The Commitment Scheme consists of the following three steps:
- Key generation: (pk, vk)← key. The key generation algorithm produces a pair of keys, the prover’s key pk and the verifier’s key vk, each of which is sent to the prover P and verifier V, respectively.
- Commitment phase: (com, d)←Com(pk, m). The Com algorithm takes as input the key of the prover and the message to be fixed. It then issues the commitment com as well as the opening value d, which will only be sent to V during the verification phase. Commitment com is sent to V.
- Verification phase: b←Ver(vk, com, m, d). The Ver algorithm takes as input the verification key vk, the commitment com, the original message m, and the opening value d . The output is a Boolean number b, that is, either success or failure.
Zero-Knowledge Proofs
A zero-knowledge proof involves two parties: the prover P and the verifier V. The verifier V asks the prover P to solve a given mathematical problem. the prover P solves the problem, but instead of sending the solution w to the verifier V, he creates a proof π, which should convince V that he solved the puzzle correctly without revealing any information about his solution.
The main purpose of zero-knowledge proofs is to allow V to easily verify that the proof π is true and thus continue the transaction.
In the case of payments, as in Bitcoin, in order for a transaction to occur between the two parties, the sender must undertake to pay a certain amount to the recipient. Therefore, a scheme is needed to make a commitment that must be binding on the sender. But the schema must also be hidden for the recipient to be properly null-knowledge-enforceable. That is, it should be impossible for the recipient to determine the exact amount of the obligation assumed, unless the sender discloses it (ie, gives the recipient the secret key to disclose the amount).
Therefore, in order for Alice to privately send coins to Bob, she needs to do two things:
First, she uses a commitment scheme to “encrypt” the value of the coins she wants to send to Bob. The fixed value is not only hidden, but also mandatory for A.
Second, Alice creates a zero-knowledge proof of π, which proves that Alice owns the coins she wants to send to Bob, but which reveals nothing about the transaction.
Alice then publishes her commitment, along with the corresponding proof of zero knowledge of π.
Note that when implementing the commitment and zero-knowledge proof scheme as described above, it is possible to hide the inputs and outputs of a state transition, but not which transition function was performed. Thus, data confidentiality is achieved, since the sender, recipient and amount sent are hidden.
ZEXE development strategy
ZEXE is a scheme for privacy-preserving decentralized applications such as decentralized exchanges. It is developed based on the ledger and supports many functionalities. These include user-defined fungible assets, cross-application communication, and public auditability. And, of course, all of this must be achieved in zero-knowledge mode.
To achieve the above goals, ZEXE differs from existing private blockchains in several ways.
- ZEXE provides a common execution environment where multiple applications interact with the same ledger.
- The content of a transaction is no longer limited to the transfer of assets, but is a more general unit of data called a record. Moreover, users can define their own functions with appropriate predicates that define the conditions under which assets can be spent without having to ask for permission.
- Instead of an on-chain execution environment, ZEXE prefers offline computing that generates transactions and attaches a zero-knowledge proof to each transaction to verify their correct execution.
- The result is a protocol for a new cryptographic primitive called Decentralized Private Computing (DPC).
Zerocash transactions
The first real system to use commitment schemes and zero-knowledge proofs for privacy was Zerocash. The tx transaction in Zerocash is an “operation” that consumes the old coin commitments as input and produces the newly created coin commitments along with a zero-knowledge proof that validates the transaction calculations.
On a ledger, each transaction consists of:
- Serial numbers of consumed coins, { sn₁, sn₂, … , snₘ},
- obligations of created coins, { com₁), com₂), … , comₙ) } , and
- Zero-knowledge proof π, confirming two facts,
- that the serial numbers consumed belong to coins created in the past (without specifying which ones, which ensures confidentiality for the parties to the transaction),
- that the obligations contain new coins of the same total value as the consumed coins (ensuring the overall economic integrity of the system).
Note that the coin liability indices in Fig. 1 are not repeated. The three new commitments are labeled 4, 5 and 6 rather than 1, 2 and 3 to indicate the uniqueness of the commitments. Likewise, each coin has a unique serial number sn, and no two coins can share the same serial number.
Thus, a Zerocash transaction is private as it only shows how many coins were consumed and how many were created, but the value of the coins is kept secret. As mentioned earlier, this ensures data privacy. And in the case where Zerocash is a single-function protocol, function confidentiality is achieved by default, since there is no need to distinguish one function from another.
Extending the Zerocash Computing Model
Zerocash has been a privacy breakthrough for distributed ledger systems. But, unfortunately, this scheme is limited in the functionality it provides. What if we want to do more than a simple private transfer of assets?
Take, for example, Ethereum, which supports thousands of individual ERC-20 “token” contracts, each representing a different currency on the Ethereum ledger. All the different cross-currency transactions involve a lot of function calls, each of which is built into specific applications. But since the internal state of each application is public, so is the history of function calls associated with each of them.
Even if each of these contracts individually adopts a zero-knowledge protocol such as Zerocash to hide the details of token payments, the corresponding transaction will still reveal which token was exchanged. Therefore, although the inputs and outputs of state transitions are hidden and thus data privacy is achieved, the functions of the transition that are performed are in the public domain. Thus, achieving feature privacy in the Ethereum model is impossible.
ZEXE was motivated by this problem. In ZEXE, the goal is not only data privacy (as in Zerocash), but also functional privacy. Thus, a passive observer of the blockchain will not know anything about the application being executed and will not be able to determine the parties involved. Therefore, the ZEXE model can support many applications such as private dApps, pools, and private coins. The programming model also allows multiple applications to interact on the same ledger as well as promote custom features to achieve a fully decentralized system.
The verifier’s dilemma
Another attractive attribute of ledger-based systems is the ability to be audited. Whether a regulator or a new blockchain user, being able to easily verify the validity of historical transactions is critical.
Unfortunately, in many systems, auditability is achieved by directly checking state transitions. And this method of verifying transactions, unfortunately, involves re-executing the corresponding calculations. The problem with this method is that large calculations take a long time to complete, making the network susceptible to denial of service (DoS) attacks.
Early smart contract blockchains like Ethereum solved this problem with a gas mechanism, forcing users to pay for longer computations, which acted as a deterrent against DoS attacks. The disadvantage of this approach is that verification is still expensive. Moreover, unlike solving the Proof-of-Work problem to find the next block, verifying transactions is not profitable. This problem is known as the verifier’s dilemma. In the past, this problem has caused breaks in well-known blockchains such as Bitcoin and Ethereum.
Unlike other blockchains, program execution in ZEXE takes place off-chain. Moreover, due to the use of zk-SNARKs, verification of proofs is cheap for miners or on-chain validators. Thus, ZEXE effectively solves the verifier’s dilemma.
Achieving Zero Knowledge
Let’s start with Zerocash, a protocol designed for applications with a single functionality, that is, for transferring value within a single currency. Zcash is one example of a cryptocurrency system that uses the Zerocash protocol. It uses zero-knowledge proofs (zk-SNARKs) to achieve privacy. The purpose of ZEXE is to extend this protocol beyond individual applications to any arbitrary program.
Records as units of data
The first step is the transition from coins to records as units of data. That is, instead of an integer value, the entry stores an arbitrary data payload. Thus, instead of simply passing a value, as in Zerocash, ZEXE works with arbitrary functions if they are known to everyone in advance.
This change allows ZEXE to support arbitrary programs. But what about privacy?
In the public eye, a transaction can again be thought of as an operation that consumes old write commitments and emits newly created commitments along with a zero-knowledge proof.
When a record is created, its liability is published on the ledger, and its serial number is published only after the record is consumed. This time, the zero-knowledge proof confirms that applying the function to the old entries resulted in new entries.
As with Zerocash, each transaction on the ledger consists of,
- Sequence numbers of consumed records, { sn_(old₁), sn_(old₂), … , sn_(oldₘ) },
- Obligations of Created Records, { com_(new₁), com_(new₂), … , com_(newₙ) } , and
- Proof with zero knowledge of π, confirming two facts,
- firstly, that the serial numbers belong to records created in the past (without revealing the records),
- Secondly, that the obligations contain new entries with an equivalent total value of the consumed entries.
Arbitrary function support
The second step is to allow multiple users to freely define their own functions and let the functions interact without any rules. This can be achieved using the same approach described in the previous step. That is, by allowing the user to capture a single function Φ that is generic, and then interpret the data payload dpᵢ as user-defined functions Φ = dpᵢ that are provided as inputs to Φ.
Using zero-knowledge proofs like in Zerocash will keep the features private. However, simply allowing users to define their own functionality does not, by itself, produce useful functionality in general.
Feature privacy is problematic in this scenario because there is no way for users to determine whether a given record was created under a feature in a legitimate way. And given the inevitable presence of malicious users, honest users are thus not protected from all types of fraud.
This particular design approach, which assumes unlimited freedom for users to freely define functions, is, of course, extreme. The lack of rules governing the interaction of user-defined functions is the root of its failure. But can this idea be saved? The answer is yes, and we’ll see how to do it in the next section.
Using tags to identify features
The third step in this design path is to introduce unique identifiers for each user-defined function Φ. That is, we include an identifying function tag in each entry and use the id tag as a way to identify which function was used to create the entry. This can be done in a zero-knowledge way. Perhaps the label id is defined as the hash value of the function Φ evaluated for a given value of vᵢ. That is, idᵢ = H(Φ (vᵢ)). And, therefore, each Φ function will have a unique id tag idᵢ if the hash function is collision resistant.
Since “no rules” was the main problem in the previous fraud approach, one rule can be applied in this case. That is, only records with the same id tag are allowed to collaborate in the same transaction.
Zero-knowledge proofs can ensure that records participating in the same transaction actually have the same functional id tag. This ensures that only records created by the same function participate in the same transaction.
While this type of system provides reasonable functionality, it suffers from complete and total separation of processes. As a result, even a simple exchange of coins cannot be achieved. However, this is a step in the right direction.
Decentralized Private Computing
The idea of a nano-core of records is central to ZEXE and allows for a new cryptographic primitive called Decentralized Private Computing (DPC). DPC is a ready-to-use framework that any developer can use to build their own applications. Transactions in the DPC scheme are executed according to RNK. They are decentralized by definition because RNK gives users control over defining the conditions under which their assets can be used through custom birth/death predicates.
Nano core records
Continuing to reveal the design of ZEXE, the next design phase was to strike a balance between the two aforementioned extremes in design. That is, support for arbitrary functions and the use of tags to identify functions.
Recall that the purpose of ZEXE is for parallel processes to share a ledger without violating each other’s integrity or confidentiality. Therefore, some kind of operating system is needed to manage user functions. Such management means
The authors of ZEXE set out to formulate a minimalist co-execution environment that imposes simple yet expressive rules on how records can interact. This is the “nano-kernel” that manages the records and is therefore called the Records Nano-Kernel (RNK). RNK provides records management by allowing users to define special functions that check the validity and validity of records consumed or created. Thus, records can participate in transactions only if they satisfy these functions.
Therefore, the record carries more information than usual. It contains a data payload as well as two user-defined functions called predicates: a birth predicate, which is executed when r is created, and a death predicate, which is executed when r is consumed.
By programming these two predicates appropriately, the user completely dictates the conditions under which the record r is created or consumed. The predicates of all records participating in a transaction receive the transaction’s local data as a common input. The local transaction data contains: the contents of each entry, the transaction memorandum (ie the public part of the shared memory), the auxiliary input (ie the hidden part of the memory), and any other construct-specific data.
Thus, each predicate can independently check whether the local data is valid according to its own logic. In this way, the entry can be protected from other entries that may contain “bad” birth or death predicates, since they must be “False”, given the local data intended for another function.
As before, zero-knowledge proofs ensure that the death predicates for consumed records and the birth predicates for created records are satisfied.
Examples of predicates within RNK
The following examples illustrate how RNK can be used to develop applications such as custom assets and notional exchanges.
Example 1: Custom Tokens or Digital Assets
Consider an example of using custom digital assets. In this case, we want to create assets and save them afterwards. Therefore, we can use payload records that encode the asset identifiers id, the asset’s initial offer v, and the value v. That is payload=(id,v,v=v).
We fix the birth predicate in all such records as a mint-or-conserve function, MoC. This means that the MoC is responsible for creating a stock of the new asset and then storing the value. An entry with asset id either creates an initial supply of a new asset (“mint”) or ensures that the total supply of the asset in circulation does not increase when transferred between parties (“conserve”). The bottom line is that a record does not create an asset, but in a sense it is an asset itself!
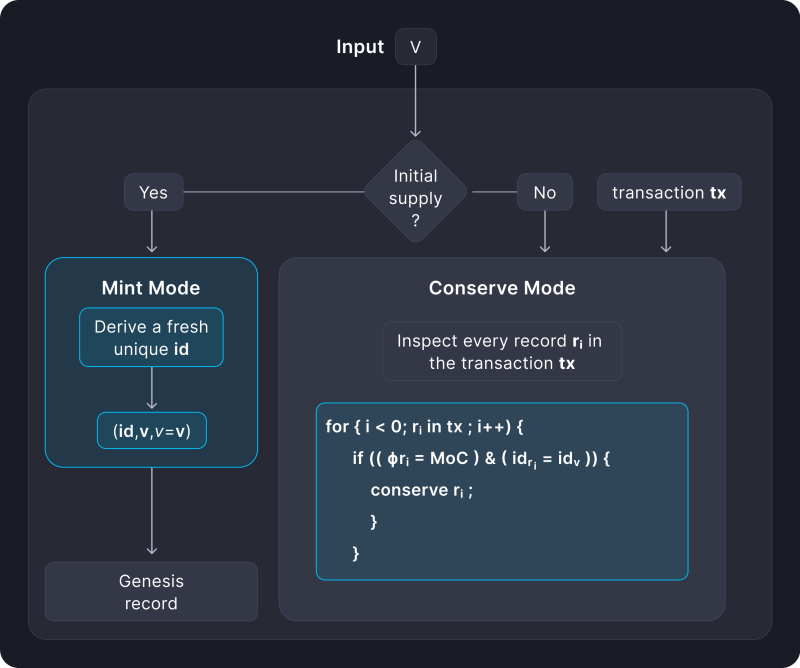
In addition to creating custom assets, users can program record death predicates to enforce conditions on how assets can be consumed and thus implement conditional exchanges with other parties.
If Alice wants to exchange 100 units of asset id_1 for the equivalent 50 units of asset id_2, she creates an entry r with 100 units id_1 whose death predicate stipulates that any transaction tx consuming r must also create another entry accessible only to Alice with 50 units asset id_2.
It then publishes the out-of-band information about r so that anyone can later claim it by creating a transaction in which the exchange will be made.
By design, death predicates are arbitrary, so different access policies can be implemented. For example, a user may require that a transaction to buy a record
- must be authorized by two of the three public keys (i.e. by some multi-party computation),
- becomes valid only after a certain time has elapsed since its creation (using temporary locks), or
- must expand the hash preview.
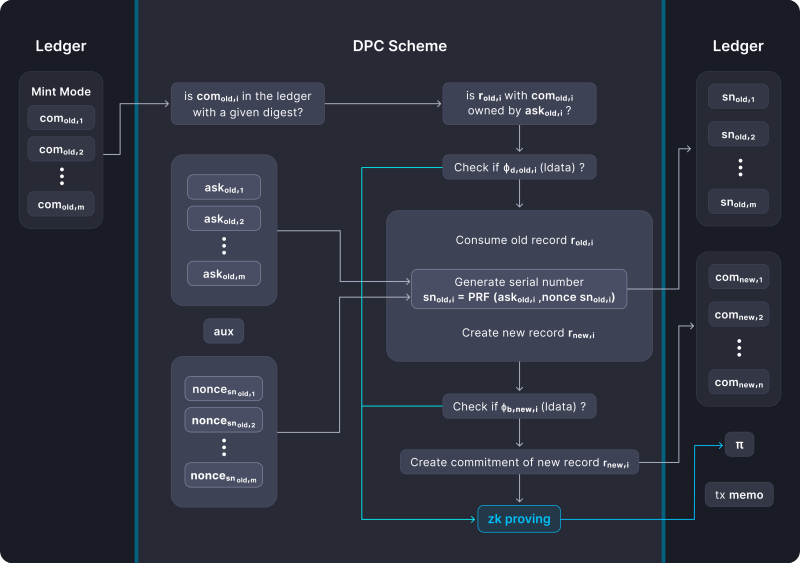
Transactions within RNK
In ZEXE, generating a transaction involves creating commitments for new entries as well as calculating unique serial numbers for used entries (similar to ZCash). It is important to note that each record commitment requires the public key of the address of the owner of the record ‘apk’ and a nonce serial number. Likewise, the serial number of the consumed record r cannot be created without the serial number of the nonce r and the owner’s address private key ‘ask’. The serial number of nonce r is actually the output of a collision-resistant hash function that takes unique information about the transaction that created r .
Note that the private key of the ‘ask’ address is always taken as input when generating the public key of the ‘apk’ address. A transaction in Bitcoin or Zcash, for example, only allows the user to spend the coin if they are in possession of the private key. In ZEXE, the idea is much the same. RNK adds to the same condition for wasting records that all relevant predicates given by the user who created the records to be spent must be simultaneously satisfied.
The same conditions govern the generation of zero-knowledge proofs that prove that the birth and death predicates have been evaluated correctly on the provided local data. Therefore, if the user knows the secret keys of the records to be consumed, and if all relevant predicates are satisfied, then the user can create a zero-knowledge proof to be attached to the transaction.
Note about RNK
RNK is not a scripting mechanism, as in Bitcoin, but a structure that supports arbitrary programs. These programs can be executed either within a single transaction or across multiple transactions by storing appropriate intermediate state data or messages in the record payload, or by publishing this data in transaction memos (in plaintext or ciphertext, as appropriate). ).
Thus, transactions can implement any state transition, with consumed records being read from the blockchain and newly created records being written back to the blockchain.
Delegated DPC
Heavy computing may be unavoidable for some applications, which can cause problems for devices with limited processing power. To solve this problem, ZEXE provides another way of DPC schemes: Delegated DPC (or DDPC) schemes. This allows you to delegate labor-intensive calculations to untrusted third parties. These third parties are provided with the secrets needed to create transactions and relay the transactions back to the user because the user does not reveal the secrets needed to authorize the transactions. The trade-off of DDPC is that it no longer provides functional privacy. However, the operator cannot steal assets or deviate in any way from the user’s signed intent. Thus, DDPC provides an additional opportunity to speed up proof generation and computation time in exchange for slightly reduced privacy.
Conclusion
ZEXE was designed to provide private computing on public ledgers for arbitrary programs. This series of articles focused on the context in which ZEXE emerged among ledger-based systems, how transaction information was traditionally handled in such systems, a number of technical issues that have plagued privacy-preserving ledger-based systems, the design methods adopted authors to address these issues, and how these techniques can be implemented to achieve applications with true decentralization, complete privacy, and concise verification.
The decentralized private computing paradigm guarantees not only data privacy, but functional privacy as well. Execution is completely autonomous, and published transactions are supplemented with zero-knowledge proofs that validate calculations according to birth/death predicates. Because the user-defined predicates are included in the assertion being proved, the zero-knowledge protocol hides function calls, thus achieving function confidentiality. Because these zero-knowledge proofs are concise and their verification is cheap, ZEXE also eliminates the verifier’s dilemma.
In addition to privacy, the ZEXE approach also provides greater scalability compared to other ledger-based systems where the virtual machine is entirely on the chain. Moreover, new cryptographic technologies, such as recursive proof of composition, have the potential to increase the scalability of ZEXE by orders of magnitude.
The goal of ZEXE is to be a minimal, elegant protocol for supporting completely private applications. It expands on previous ideas to achieve both privacy and programmability, which have so far only been achieved separately in single application systems. As a result, it is an ideal platform for decentralized applications such as decentralized finance, gaming, authentication, and more. That is why we decided to make ZEXE the backbone of Aleo.