Zettabyte File System Explained
In this article, I will strive to answer many questions that have been asked about ZFS, such as what is it, why should I use it, what can I do with it, and the like? Let's begin:
Designating Hot Spares in Your ZFS Storage Pool
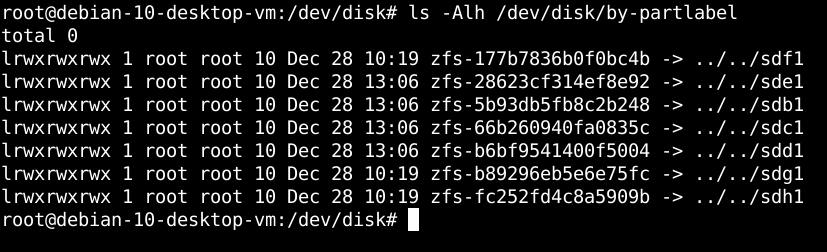
There is a feature built into ZFS called the "hotspares" feature which allows a sysadmin to identify those drives available as spares which can be swapped out in the event of a drive failure in a storage pool. If an appropriate flag is set in the feature, the "hot spare" drive can even be swapped automatically to replace the failed drive. Or, alternatively, a spare drive can be swapped manually if the sysadmin detects a failing drive that is reported as irreparable.
Setting Up Quotas & Reservations in OpenZFS in Linux
ZFS supports quotas and reservations at the filesystem level. Quotas in ZFS set limits on the amount of space that a ZFS filesystem can use. Reservations in ZFS are used to guarantee a certain amount of space is available to the filesystem for use for apps and other objects in ZFS. Both quotas and reservations apply to the dataset the limits are set on and any descendants of that dataset.
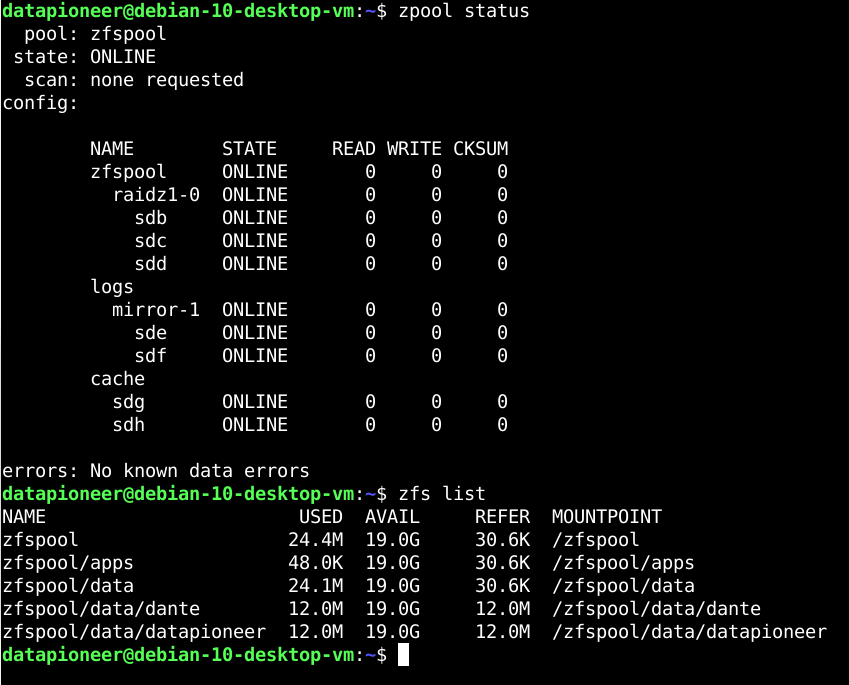
Logs Mirror, Cache, & Snapshots in OpenZFS Filesystem on Linux

Another big advantage to installing ZoL or OpenZFS filesystem on Linux is that as the sysadmin you can create a mirror of two SCSI drives in the filesystem containing your system logs and create a cache consisting of two SSD drives in the filesystem containing system cache information. The logs mirror helps to balance the load of the ZFS pool in the system and also helps to ensure that your log files are preserved in the event of RAIDZ failure. The cache is a part of the ARC (Adaptive Replacement Cache) system in OpenZFS and assists in rebuilding drives to restore your system if drives begin to fail. Read cache is referred to as L2ARC (Level 2 Adaptive Replacement Cache), synchronous write cache is ZIL (ZFS Intent Log), SLOG (Separate...
Investigating RAIDZ in Debian 10 "Buster" Linux

Now that we have looked at implementing OpenZFS on Linux in Debian 10 Linux and created zfs pool mirrors using OpenZFS as well as created and accessed ZFS datasets on the system, let's turn our attention to implementing RAID in OpenZFS. How does implementing RAID in OpenZFS compare to traditional RAID solutions? Is there a one-to-one correlation between RAIDZ and traditional RAID? Are there advantages to running RAIDZ rather than the traditional RAID solutions?
Installing and Using OpenZFS on Debian 10 "Buster" Linux
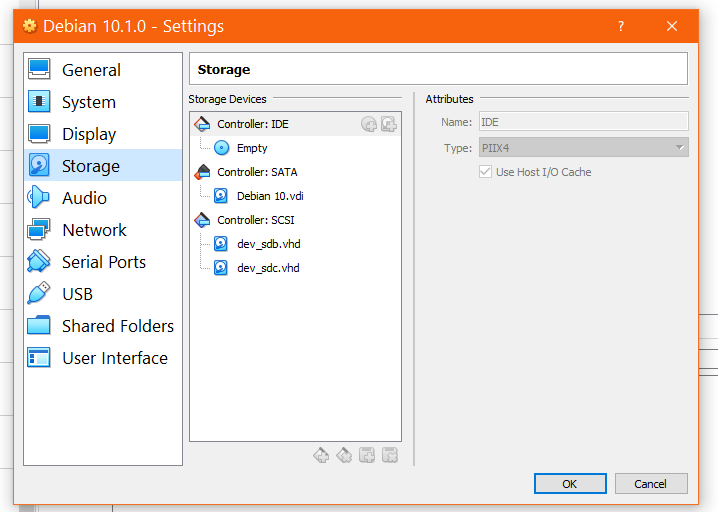
I am running Debian 10 "Buster" Linux in Virtual Box 6.0 Manager on my Win10 Pro Main PC using the debian10-1.0-amd64-netinst.iso file which I downloaded from the Debian Linux download page. This distro was originally installed as a VM using the ext4 filesystem for the primary partition represented as /dev/sda1 in the system. I wanted to experiment with using ZFS (ZetaByte File System) which was originally developed by Sun Microsystems and published under the CDDL license in 2005 as part of the OpenSolaris operating system. I further wanted to investigate this filesystem over others that are traditionally used in Linux, such as ext3/ext4/btrfs because ZFS is known for two specific reasons: (1) It stores large files in compressed format...
Accessing an OpenZFS Mirror Created in Debian 10 Linux

Now that we have created the ZFS Mirrors in the Linux system which point to four other SCSI drives of 10G capacity each, our two existing mirrors of two drives each are theoretically capable of accessing data of at least 20G in size. However, due to the overhead for keeping track of this data in the filesystem, our Linux system show a total data access space of around 19G.
Setting Up a NAS Solution Running in Debian Linux
Recently, I setup a secondary network-attached storage (NAS) solution at home using a virtual machine rather than a bare metal PC/server as a test platform. The process for setting this up is rather easy and anyone can do it. As I stated here, this is a secondary NAS solution since I already have a 5TB WDMyCloud Personal Cloud which I have had in place in my home running on my LAN now for several years.