Подмена в прогнозах, которой никто не рад

Рассмотрим неприятную задачу подмены значений в прогнозах, вызванную изменениями в первоначальных условиях использования модели машинного обучения. В реальной жизни время от времени такое происходит и надо быть к этому готовым.
Рассмотрим вопрос на примере системы предсказаний потребления объектами товаров. Сгенерируем синтетические данные (использованные приемы описаны ранее):
import pandas as pd
import numpy as np
np.random.seed(0)
# предсказания количества item-ов для объектов
items = ['item1','item2','item3','item4','item5']
all_df = pd.MultiIndex.from_product([np.arange(5), items]).to_frame()\
.reset_index(drop=True).rename(columns={0:'objs', 1:'items'})
preds_df = pd.concat([all_df.sample(10).reset_index(drop=True),
pd.Series(np.random.randint(100, size=10), name='preds')], axis=1)
preds_df.sort_values(by='objs')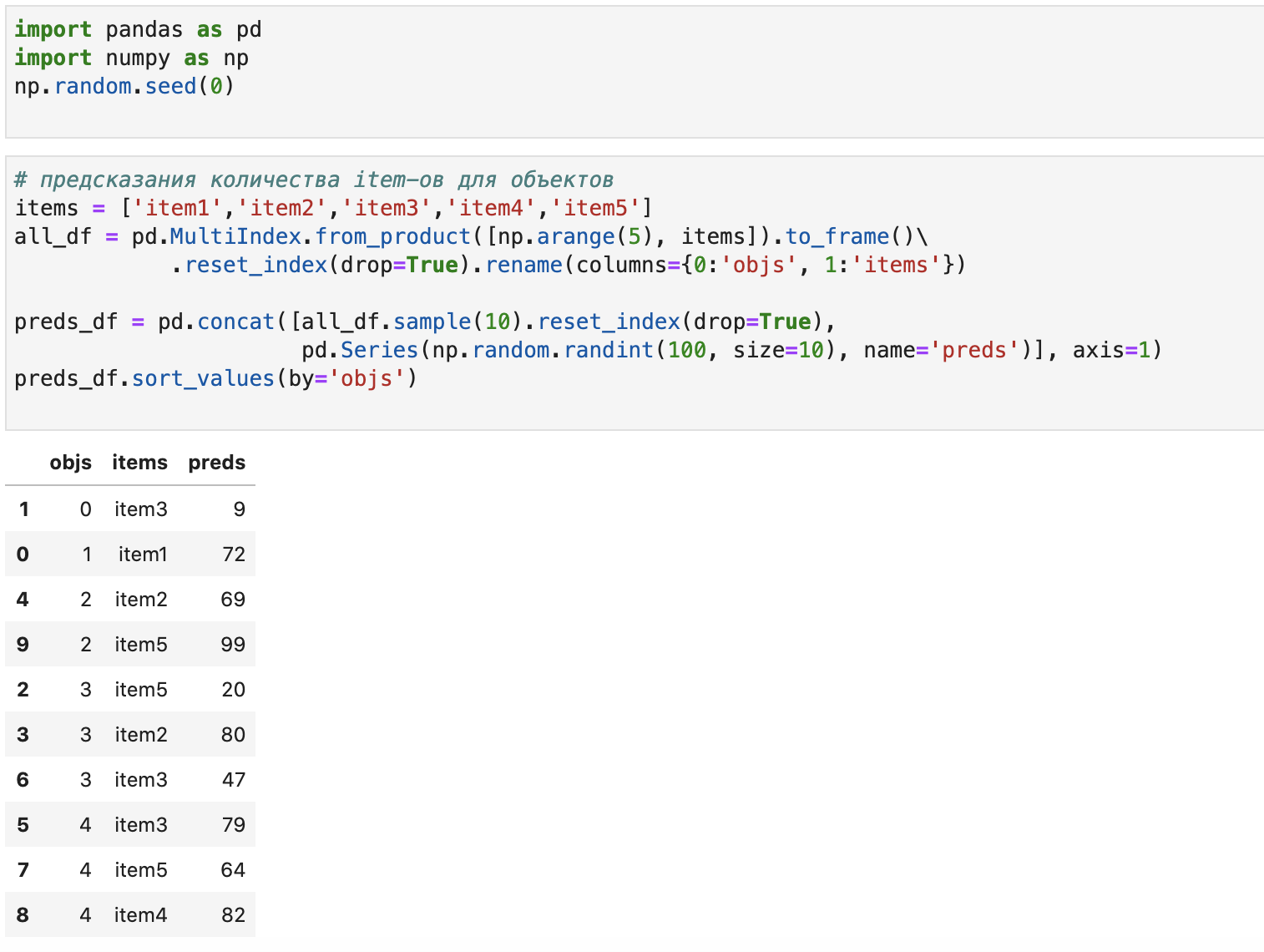
objs, items задают пары объектов и товаров, для которых мы делаем предсказания. Подмена так же осуществляется для пары, например, филиал организации использовал картриджи двух типов, а теперь только одного.
Правила замены определяются исходя из перечня имеющихся на obj item-ов (например, всех используемых в филиале товаров, зададим в obj_items_df) и словаря замены (например, вместо item1 - item2 /шариковые -> гелевые ручки, зададим в maps_d):
# что имеется на объектах obj_items_df = preds_df.copy()[['objs', 'items']] obj_items_df.drop([7], inplace=True) obj_items_df.sort_values(by='objs')
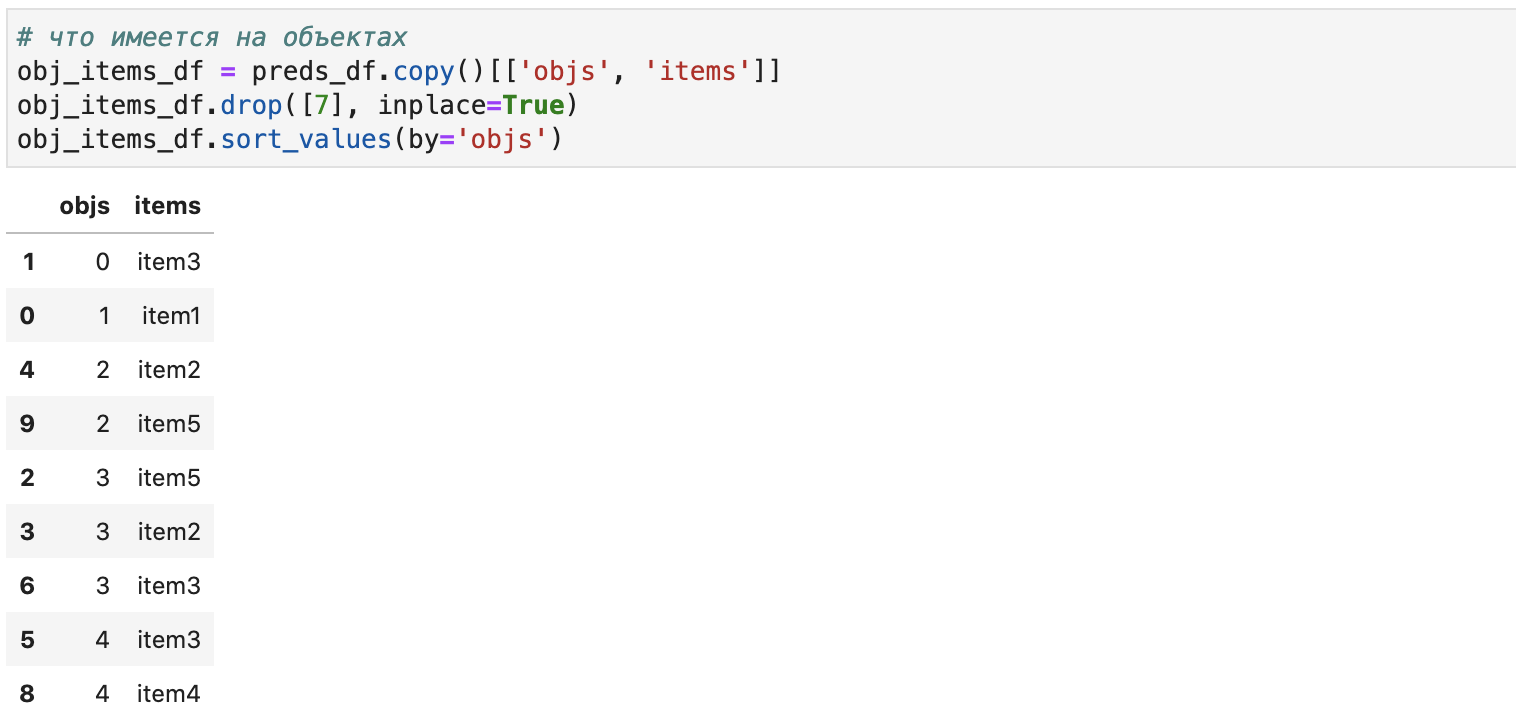
maps_d = {'item1':'item2', 'item2':'item1', 'item3':'item5', 'item5':'item3'}Отмечу, что к описанной логике замены, базирующейся на перечне всех имеющихся на объектах товаров, можно перейти, имея список отсутствующих номенклатур, следующим образом:
obj_items_minus_df = pd.MultiIndex.from_tuples([(4,'item5')]).to_frame().\
reset_index(drop=True).rename(columns={0:'objs',1:'items'})
obj_items_df = preds_df.copy()[['objs', 'items']]
obj_items_df = obj_items_df[~((obj_items_df['objs'].isin(obj_items_minus_df['objs']))&
(obj_items_df['items'].isin(obj_items_minus_df['items'])))]
obj_items_df.sort_values(by='objs')
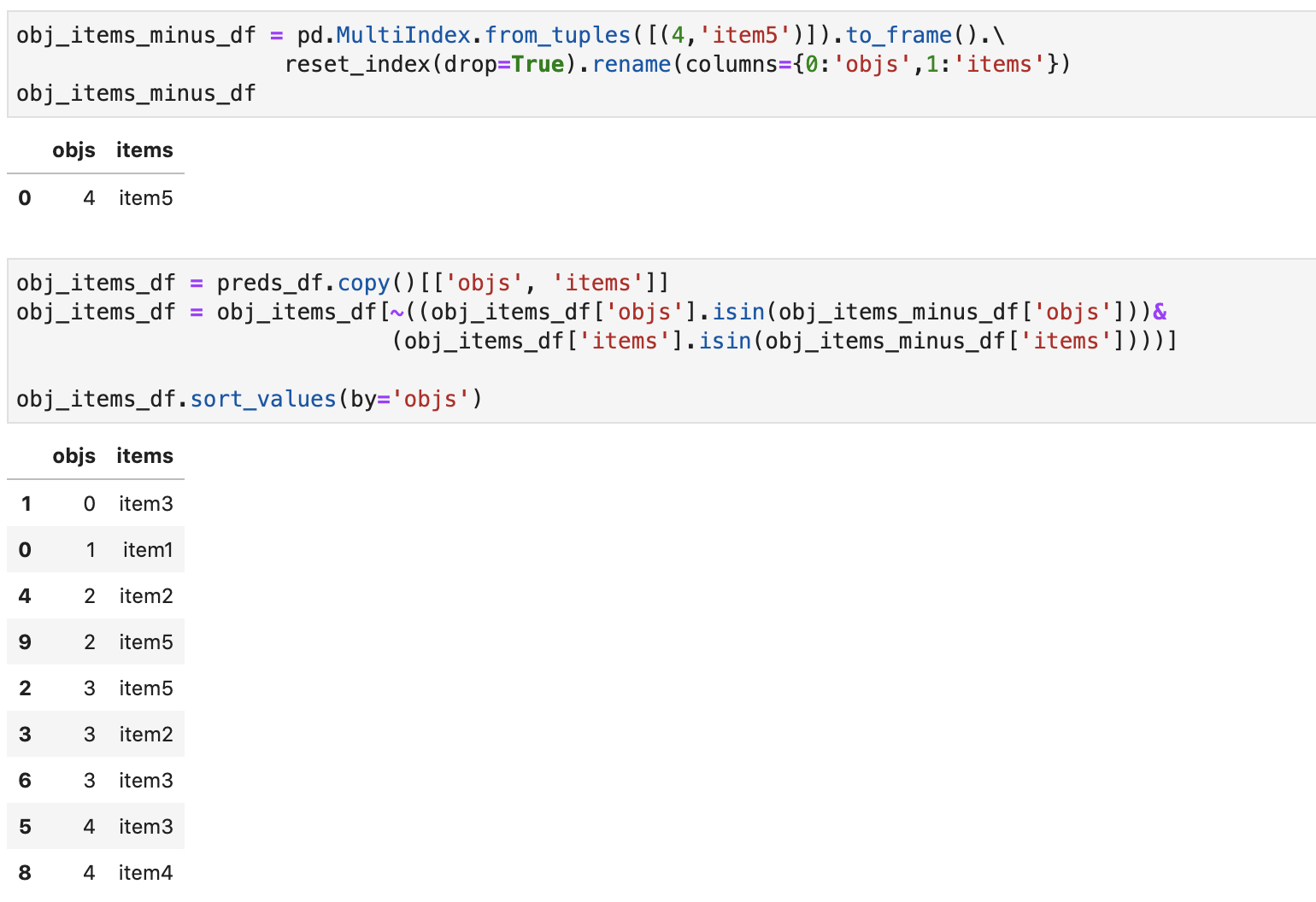
Теперь перейдем к функции подмены - change_items. Ее логика предполагает фильтрацию и замену значений на уровне индексов Pandas, так как этот способ работает быстрее других (детальнее рассказывал ранее) . Код функции описан ниже:
def change_items(preds_df, obj_items_df, maps_d, minus=False):
''' input - preds_df with cols objs,items,preds
obj_items_df - objs,items
maps_d - vocab of item transforms
minus - if obj_items_df is a collection of to be excluded examples
'''
if minus:
obj_items_minus_df = obj_items_df.copy()
obj_items_df = preds_df.copy()
obj_items_df = obj_items_df[~((obj_items_df['objs'].isin(obj_items_minus_df['objs']))&
(obj_items_df['items'].isin(obj_items_minus_df['items'])))].drop('preds',axis=1)
else:
obj_items_df = obj_items_df.copy()
cols = obj_items_df.columns
obj_items_df['flag']=1
obj_items_flag = obj_items_df.set_index(['objs','items'])
preds_ser = preds_df.set_index(['objs','items'])
obj_items_flag = obj_items_flag.reindex(preds_ser.index)
match_data = np.where(obj_items_flag['flag'].notnull(), obj_items_flag.index.map(
lambda x: (x[0], (x[1], x[1]))),
obj_items_flag.index.map(lambda x: (x[0], (x[1], maps_d.get(x[1], x[1])))))
match_df = pd.MultiIndex.from_tuples(match_data).to_frame().reset_index(drop=True)
match_df[cols[1]] = match_df[1].str[0]
match_df['items_new'] = match_df[1].str[1]
match_df.drop([1], axis=1, inplace=True)
return match_df.rename(columns={0:cols[0]})Ниже представлены результаты ее работы:
# match_df = change_items(preds_df, obj_items_df, maps_d)
match_df = change_items(preds_df, obj_items_minus_df, maps_d, minus=True)
res_df = preds_df.merge(match_df, on = ['objs', 'items'], how='outer').drop('items', axis=1).rename(
columns = {'items_new':'item'})
res_df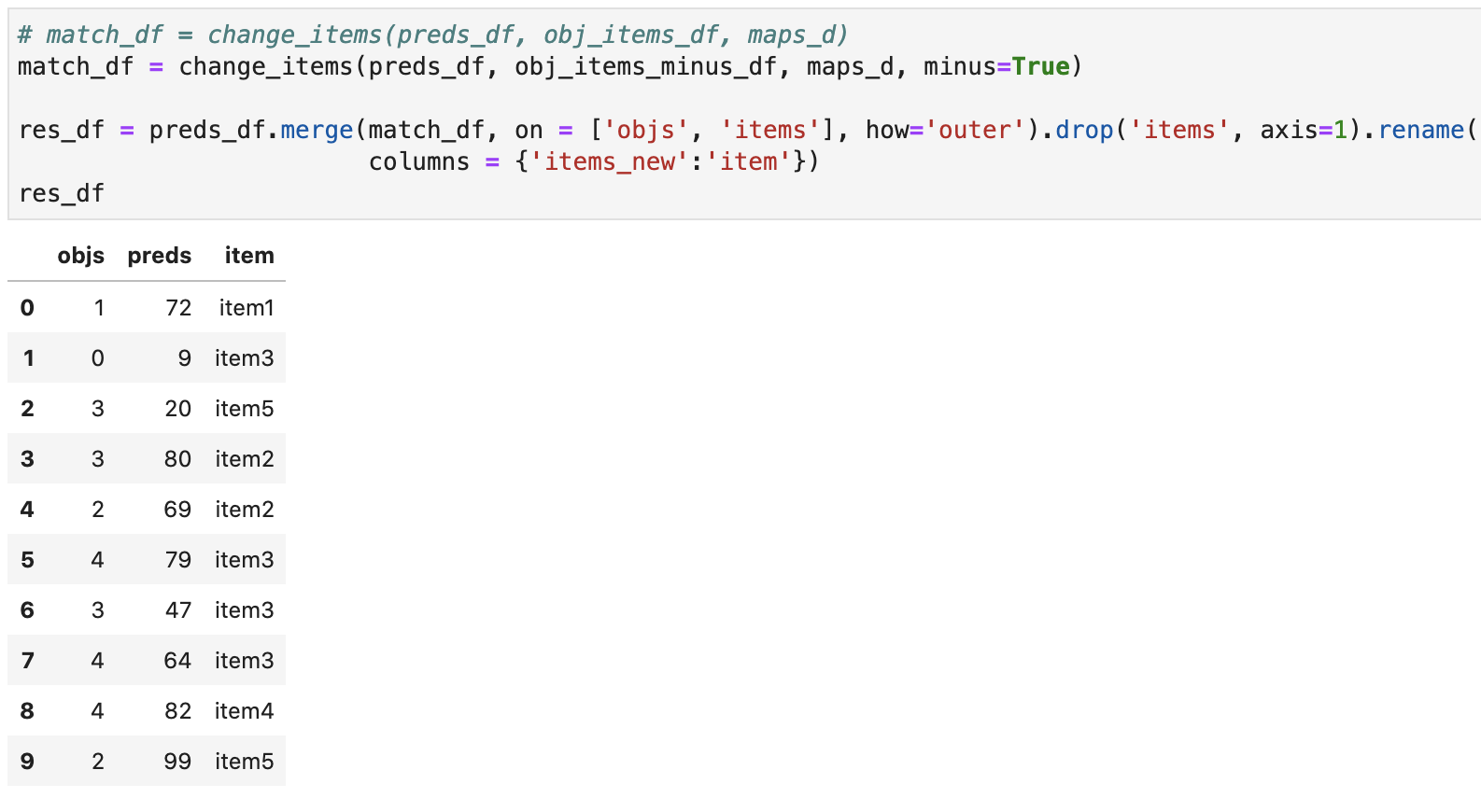
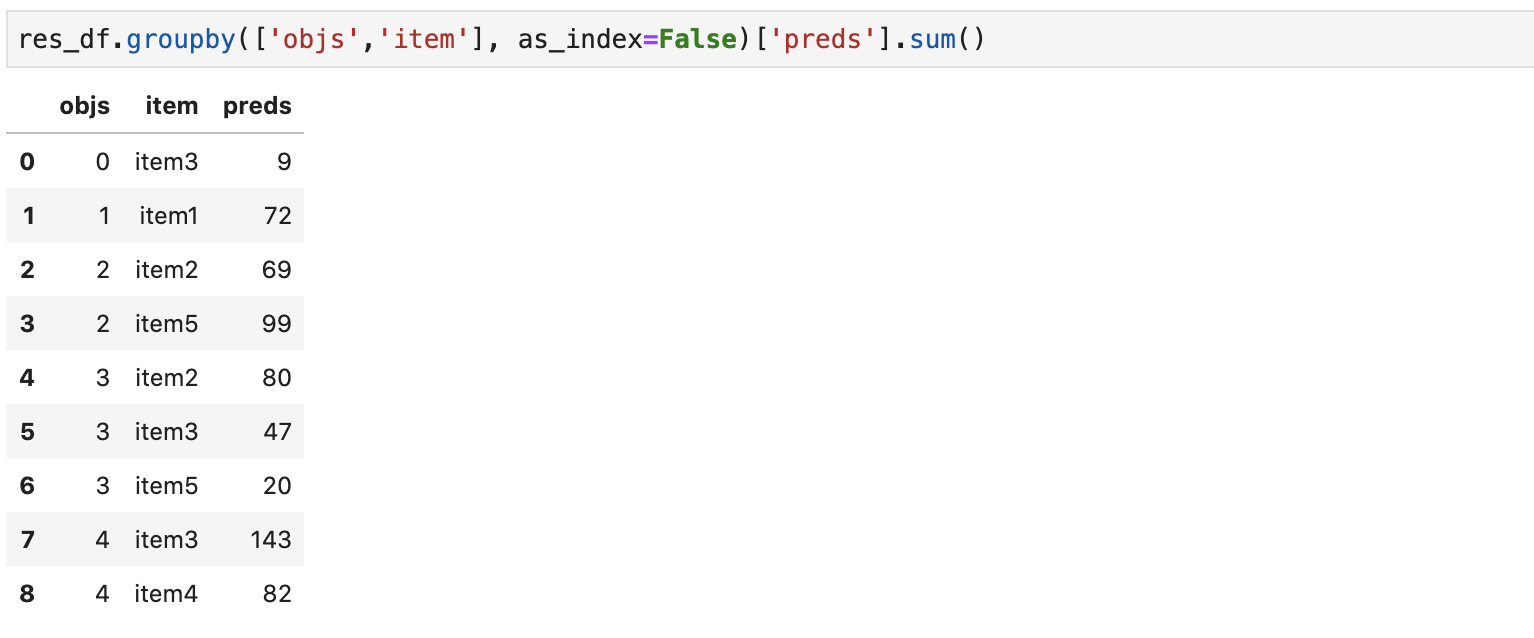
Теперь может понадобиться агрегировать прогнозы с повторяющимися item-ми (например, прогнозировали картриджи двух типов, а теперь используется только один, соответственно, и количество потребуется просуммировать):
res_df.groupby(['objs','item'], as_index=False)['preds'].sum()
Не пропустите ничего интересного и подписывайтесь на страницы канала в других социальных сетях: