Визуализация ошибок, как навигатор к скрытым проблемам модели

Визуализация — это язык, который позволяет нам видеть данные и понимать их смысл. Простой и эффективный способ диагностики результатов работы модели на различных объектах заключается в анализе разницы между прогнозами и целями. Он может показать, что в некоторых группах поведение модели имеет особенности (например, склонность к завышению или занижению прогнозов). Для демонстрации того, как строится такая визуализация загрузим набор данных:
Особенности работы с LLM нейросетями в части исправления ошибок в ответах

После релиза ChatGPT сверхпопулярным направлением стало создание промтов. Появилось много "экспертов", каждый из которых пытается предложить рецепт подходящего запроса. Пройдусь по одному из трендов - это расхожие фразы, которые призваны устранить логические ошибки .
Систематизация сценария с dvc пайплайнами

В этой статье я расскажу, как систематизировать ваш сценарий, сделать код и данные воспроизводимыми с dvc пайплайнами.
Получение доступов к 3 лучшим бесплатным чат-ботам ChatGPT, GigaChat, YaGPT 2

Заходим на сайт с использованием VPN, Затем нажимаем "sign up":
Динамическая загрузка модулей в Python и как она спасает при работе с pyspark

"Приобретение знаний - это как путешествие в неизведанные земли: чем больше вы исследуете, тем больше открытий вы делаете".
Создание списков, ссылок и якорей с Markdown

Для задания списков из нескольких уровней нужно создавать их с новой строки и предварять символами табуляции. При этом каждый очередной элемент не должен отступать от соседнего более чем на один символ табуляции:
DBSCAN для кластеризации и обнаружения аномалий

Рассмотрим один из передовых методов кластеризации - DBSCAN. Для многих исследователей эффективность метода зачастую компенсируется сложностью его настройки, из-за чего предпочтение отдается другим алгоритмам. Давайте внесем ясность в вопрос и упростим задачу использования DBSCAN.
OSINT по справочнику Linux
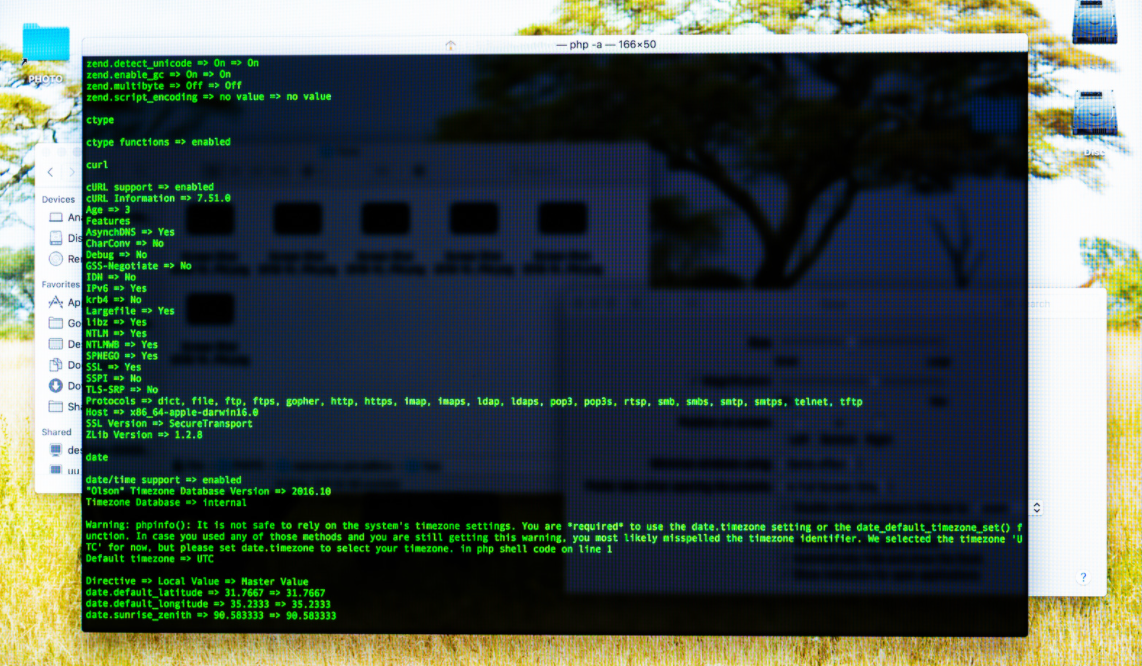
Ниже расскажу, как правильно использовать справочник Linux, чтобы получить полное и быстрое понимание возможностей командной строки. Этот навык очень важен для любого разработчика и аналитика, которые вынуждены писать код на серверах компаний и пользоваться терминалом Linux.
Как настраивать виртуальное окружение для работы со Spark

Интерактивная работа со Spark имеет свои особенности, главная из которых - всегда учитывать, что исполнение кода происходит на нескольких узлах. Одним из следствий этого является необходимость создания одинаковой виртуальной среды на нодах, так как иначе вы не можете гарантировать корректную работу. Это касается не только импортированных модулей, но и версии интерпретатора.
Неочевидные способы подбора количества групп для агломеративной кластеризации

В этой задаче библиотека scikit-learn нам не поможет, поэтому обратимся к SciPy. Для начала следует воспользоваться функцией linkage из scipy.cluster.hierarchy, которая и проведет процесс кластеризации (ранее я разбирал ее работу). В третьей колонке она возвращает дистанцию между объединяемыми кластерами (из первого и второго столбцов). На ее основании можно и задать предельный порог, после которого дистанция считается существенной и кластера перестают объединяться: