Машинный перевод на основе нейронных сетей

Заключительная глава о машинном переводе.
Машинный перевод на основе нейросетей, или системы машинного перевода «глубинного обучения» (Deep learning machine translation), как их называют сейчас, впервые стали применяться в программах по распознаванию речи с начала 90-х годов. Первое научное исследование об использовании нейронных сетей в машинном переводе было опубликовано в 2014, со множеством последующих преимуществ таких систем (большие словарные базы, возможность использования для идентификации графической информации, перевод субтитров, мультиязычность).
Нейронные сети изначально были вдохновлены биологическими нейронами человеческого мозга, в котором нейроны передают и обрабатывают базовую информацию, из которой мозг затем выстраивает более сложные концепты и идеи. Искусственные нейронные сети, как и человеческий мозг, в состоянии строить более сложные концепты из разных частей информации, собранной на иерархической структуре.
Как отмечает Иан Гудфеллоу,[1] современный термин «глубинное обучение» выходит за рамки нейрононаучной перспективы для текущего поколения систем машинного перевода. Он обращается к более общим принципам, множественным уровням обучения, которые применяются в машинном обучении, необязательно основанных на нейронных сетях.
Применительно к машинному переводу, системы глубинного обучения сделали возможным алгоритмы, где лишь несколько параметров настраиваются вручную, а идея состоит в том, чтобы система сама могла выбирать лучшее соответствие, основываясь на своей базе данных. С этой точки зрения, данная идея уже была представлена в чисто статистических моделях перевода, но на практике все равно множество параметров приходилось настраивать вручную. Например, в пяти рассмотренных нами выше системах IBM, каждая новая модель была прописана вручную и призвана скорректировать недостатки предыдущей.
Системы глубинного обучения, напротив, делали возможным, по крайней мере в теории, сделать процесс обучения полностью автоматическим, основываясь на имеющихся в его распоряжении данных, без всякого постороннего человеческого вмешательства.
Система перевода таким образом основывается исключительно на глубинном обучении и состоит из энкодера (анализирующего обучающие данные) и декодера (той части системы, которая автоматически производит перевод, базируясь на данных, проанализированных энкодером). В отличие от статистических моделей, где энкодер и декодер используют комбинации из нескольких модулей (модель языка, модель перевода для работы энкодера), чтобы иметь возможность использовать разные стратегии для оптимизации перевода, энкодер и декодер в системах глубинного обучения основаны исключительно на нейронных сетях.
В нейронных сетях каждое слово кодируется через вектор чисел, а затем все векторы слов последовательно соединяются, чтобы предоставить перевод всему предложению. Анализ последних публикаций по нейронному машинному переводу,[2] позволяет сделать вывод, что нейронный машинный перевод применяет более традиционную архитектуру, чем статистические модели, так как энкодер в данной модели может рассматриваться как анализатор языка-источника, в то время как декодер генерирует перевод, который, опираясь на треугольник Вокуа, можно описать следующим образом (1):
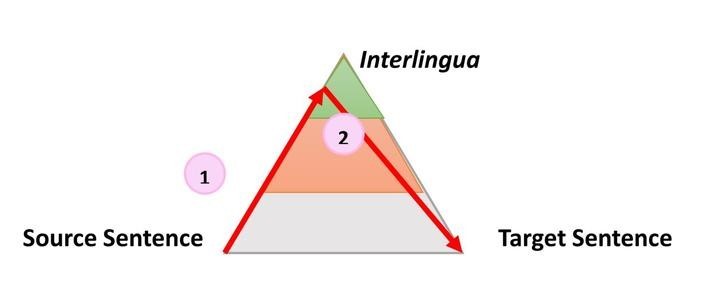
Машинный перевод на базе нейронных сетей [там же] имеет ряд своих характерных особенностей:
1. «Анализ» называется кодированием, а его результатом является некая последовательность векторов.
2. «Перенос» называется декодированием и непосредственно генерирует целевую форму без какой-либо фазы генерации.
3. Процесс перевода разбит на две фазы. В первой каждое слово
переводимого предложения проходит через «кодер», который генерирует «исходный контекст», опираясь при этом на текущее слово и предыдущий контекст (2):
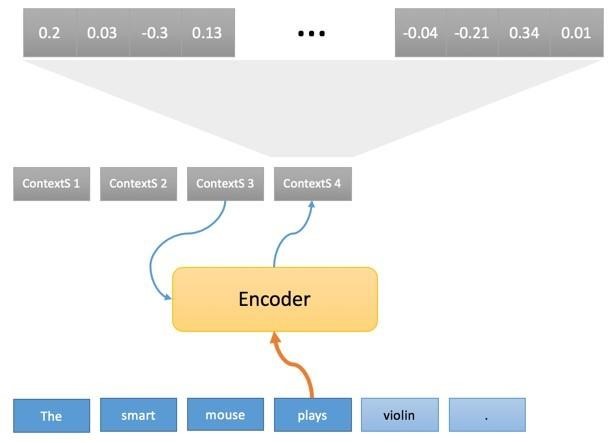
4. Последовательность исходных контекстов (ContextS1, <…> ContextS5) является внутренней интерпретацией исходного предложения по треугольнику Вокуа и представляет из себя последовательность чисел с плавающей запятой (обычно 1000 чисел с плавающей запятой, связанных с каждым исходным словом) (3).
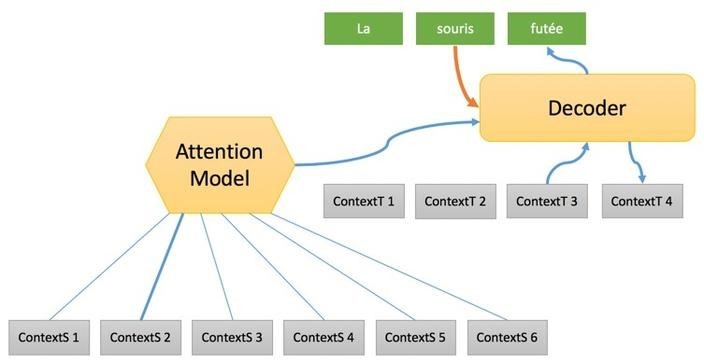
5. На втором этапе формируется полная последовательность с упором на «исходный контекст», после чего один за другим целевые слова генерируются с использованием:
– «целевого контекста», сформированного в связке с предыдущим словом и предоставляющего некоторую информацию о состоянии процесса перевода.
– значимости «контекстного источника», представляющего собой сборку различных «исходных контекстов» опирающихся на «Модель внимания» (Attention Model), которая выбирает исходное слово для использования в переводе на любом этапе процесса ранее приведенного слова с использованием вложения слов для преобразования его в вектор, который будет обрабатываться декодером.
6. Перевод считается завершенным, когда декодер доходит до этапа генерации фактически последнего слова в предложении.
Данные системы принято считать иерархическими, хотя, как замечает в своей работе Т. Пуабу,[3] на самом деле они являются многоаспектными, что означает, что каждый элемент (слово, фраза) расположен в пределах более широкого контекста. Данный подход основан на гипотезе, что слова, появляющиеся в похожем контексте, могут иметь схожее значение. Таким образом, система пытается определить группу слов, появляющихся в схожем переводном контексте.
Второй характеристикой подхода глубинного обучения является то, что эти модели являются непрерывными. Это частично касалось и статистических моделей машинного перевода, поскольку в данных системах слова рассматривались более-менее идентичными друг другу. Но в подходе глубинного обучения идея состоит в том, что слова, а также более сложные лингвистические единицы (фразы, предложения, или просто группы слов) могут быть сравнимы на более обширном пространстве, что делает данный подход более гибким и способным, например, распознавать парафраз.
Наконец, стоит отметить, что близкородственные слова внутри предложения также постепенно идентифицируются и группируются вместе в процессе анализа. Вот почему подход глубинного обучения называют иерархическим, так как он способен раскрывать структуру внутри предложения, основываясь на замеченных регулярных совпадениях из тысяч примеров, рассмотренных системой во время поиска информации. Также системы глубинного обучения напрямую не кодируют синтаксис, а, предполагается, способны идентифицировать существующие синтаксические связи в предложении. То есть, вместо того, чтобы иметь разные модули для разных частей проблемы одновременно, подход глубинного обучения предполагает, что система рассматривает все предложение без его членения на более мелкие сегменты, и что все виды отношений в контексте одновременно. Эти отношения могут иметь вертикальную (группы, или похожие слова могут заполнить позицию в предложении) или горизонтальную структуру (синтаксически связанные группы слов в предложении), что делает данный подход более адаптивным и когнитивно более интересным, но и вычислительно более сложным.
Стоит также отметить, что данный подход остается эмпирическим, особенно когда это касается определения архитектуры использованных нейронных сетей (например, число слоев рекуррентной нейронной сети, длины использованных векторов), так же как и других параметров (способы перевода незнакомых слов). До сих пор еще имеется очень небольшая теоретическая база для подобных решений, которые обычно основаны на характеристике системы и ее продуктивности. Эти системы на сегодняшний момент часто критикуют за нехватку теоретической базы.
К основным недостаткам нейронного машинного перевода можно отнести, что данные системы до сих пор хорошо справляются только с простыми предложениями и уступают статистическим моделям при переводе более сложных. Во-вторых, незнакомые слова или группы слов (т.е. слова, не включенные в обучающие данные) в основном переводятся некорректно (или не переводятся вообще).
Нейронный машинный перевод хорошо себя зарекомендовал с короткими предложениями родственных языков и, в последнее время, с длинными предложениями более генетически далеких языков. Прогресс заметен уже сейчас, и подход «глубинного обучения» может рассматриваться как революция в области машинного перевода, каким был статистический перевод в 90-х. Что послужило значительным стимулом его широкого распространения. Все основные компании в области машинного перевода (Google, Bing, Facebook, SYSTRAN) уже используют данный подход с 2016 года для своих онлайн-систем.
На контрасте, статистическому машинному переводу потребовалось несколько лет, чтобы вытеснить rule-based системы. Распространение нейронного машинного перевода происходит гораздо быстрее. Это также означает, что данный подход более адаптивный и прогрессивный, чем статистический.
References
[1] Goodfellow, I. Bengio,Y, Courville A. Deep Learning. The MIT Press, 2016, p. 13.
[2] 1. Poibeau, Thierry. Machine Translation. The MIT Press, 2017, p. 189.
2. SYSTRAN Blog «How does Neural Machine Translation work?» (2016) Published online.
[3] Poibeau, Thierry. Machine Translation. The MIT Press, 2017, p. 189.
Machine Translation Omnibus
Машинный перевод на основе примеров
Машинный перевод на корпусах текстов
Машинный перевод на основе правил
Сколько всего видов машинного перевода?
От Декарта до Google Translate. Удивительная история машинного перевода