Статистический машинный перевод

Немного о теореме Байеса...
В конце 80-х годов исследовательской группой IBM из Йорктаун Хайтс, Нью-Йорк было решено заняться системой машинного перевода, основанного на технике распознавания речи. Распознавание речи в данной стратегии сводилось к задаче письменного воспроизведения речевого высказывания. Перевод при подобном подходе виделся похожим процессом, с одной лишь разницей, что входной сигнал здесь – последовательность слов исходного языка вместо звукоряда.
Эти эксперименты IBM были описаны в целой серии научных публикаций,[1] датированных серединой 80-х – началом 90-х годов. Отправной точкой исследователями был принят факт, что всегда есть несколько возможных вариантов перевода одного и того же предложения, вне зависимости от языка-источника и языка перевода. Выбор конкретного перевода среди возможных вариантов в некоторой степени – дело вкуса и индивидуального выбора переводчика. Принимая во внимание данный факт, можно предположить, что любая последовательность слов (словосочетаний) на языке перевода может в некоторой степени рассматриваться переводом некой последовательности слов исходного языка.
В статистических моделях использовались как модель перевода, так и модель языка. Сочетание данных моделей математически обосновывалось моделью «зашумленного канала»[2] (noisy-channel model). Таким образом, взяв пару двух предложений (обозначенных символами S, T), где S – это предложение на исходном языке (Source sentence), а T – предложение на языке перевода (Target sentence), то можно рассчитать математическую вероятность[3] Pr(T|S), с которой переводчик произведет перевод T для предложения S. Например, вероятность Pr(T|S) будет очень незначительной для пары предложений типа:
Le matin je me brosse les dents.
President Wilson was a good lawyer.
И значительно выше для пары предложений типа:
Le président Wilson était un bon avocat.
President Wilson was a good lawyer.
Другими словами, каждый перевод, выполняемый на переводимом языке может рассматриваться как перевод предложений на исходном языке, но реалистичный перевод всегда будет получать результат выше нуля, тогда как остальные переводы будут оставаться близкими к нулю. Исследователями IBM было продемонстрировано, что данная гипотеза может быть смоделирована, используя принципы элементарной теории вероятности, или теоремы Байеса, в следующую формулу (1):
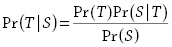
Где
Pr(T) – языковая модель,
Pr(S|T) – модель перевода.
Иными словами, Pr(S|T) определяет вероятность последовательности слов (токенов) S согласно последовательности T (имеется в виду вероятность, что S – есть некая последовательность слов в языке источника, которая соответствует некой последовательности слов языка перевода T; если вероятность близка к 1, то, вероятно, два предложения являются переводом друг друга), в то время как Pr(T) определяет вероятность последовательности слов на языке перевода, не принимая в расчет исходный язык, т.е. что вероятность T формирует адекватный и грамматически правильный перевод некой последовательности слов на языке перевода (что особенно касается порядка слов на языке перевода).
Так как знаменатель в данном уравнении (2) не зависит от T, то его можно упростить до следующей формулы:
T’ = argmaxT [Pr(T) * Pr(S|T)] (2)
Данная формула стала «фундаментальным уравнением машинного перевода» для группы IBM, так как все их модели статистического перевода впоследствии произошли именно от нее[4]. Но как замечает в своей работе Т. Пуабу[5], данное уравнение не объясняло, как анализировать исходное предложение в процессе перевода. Самый простой способ для данной модели положиться на то, чтобы словам самим сложиться в пословном переводе, по крайней мере, при первом приближении. В данном случае основной идеей являлось найти для каждого слова исходного языка адекватный перевод на языке перевода, используя очень большой выровненный на уровне предложений двуязычный корпус.
Выделяют несколько основных моделей статистического перевода:
- Основанный на слове машинный перевод (Word-based translation).
- Основанный на сегменте машинные перевод (Segment-based translation).
- Основанный на синтаксисе машинный перевод (Syntax-based translation).
- Иерархически основанный на фразе машинный перевод (Hierarchical phrase-based translation).
Первые модели статистического перевода также отталкивались от стратегии перевода по словам. В word-based модели основной единицей перевода было слово на некотором естественном языке. Основной базой данной стратегии были двуязычные словари. При статистическом подходе двуязычный словарь состоял из слов со всеми возможными вариантами его перевода с некой вероятностью их эквивалентности переводимому слову.
Чтобы помочь системе выбрать правильный вариант перевода был придуман алгоритм выравнивания слов (word aligment), который, вычисляя частотность употребления каждого слова с его переводом, высчитывал наибольшую вероятность идеального совпадения. Пять моделей, изобретенных IBM, включали в себя несколько оптимизаций, призванных справляться со словосочетаниями и словами, которым не было эквивалента на языке перевода.[6]
Модель 1 была максимально простой. По умолчанию, ей было предусмотрено, что для любого слова языка перевода есть прямой эквивалент любого слова исходного языка и все начальные выравнивания на уровне слов имеют равную вероятность (т.е. все исходные слова mS могут быть соединены со словами переводимого языка mT с одинаковой вероятностью на начальном уровне выравнивания). Следуя данному принципу, система запускала процесс, который, используя классической алгоритм обучения, называемый EM-алгоритм (expectation-maximization algorithm), высчитывал вероятность, связанную с каждой mS-mT пар, так и вероятность, связанную с каждым возможным выравниваем на уровне предложения. Применение такого алгоритма требовало очень большого объема корпуса текстов и сложные вычислительные методы, кроме того, она не учитывала порядок слов, что приводило к большому количеству ошибок.
Модель 2 исправляла недостаток первой, принимая в расчет в своих вычислениях взаимное расположение слов переводимого языка по отношению к слову на языке-источнике. Это не вносило существенных изменений в предыдущий алгоритм, но улучшило качество и скорость, с которой система находила правильный эквивалент.
Модель 3 была значительно сложнее Модели 2. Ее целью было лучше решить вопрос 1-n совпадений (когда одно слова на исходном языке переводилось несколькими на языке перевода, например, слово “potato” на английском и “pomme de terre” на французском). Также эта модель исправляла другую сходную проблему - артикли, которые есть в одних языках, и отсутствуют в других (например, чтобы перевести с французского на английский фразу“il est avocat” нужно добавить артикль “he is a lawyer”, отсутствующий во французской фразе). Для предыдущих моделей это была невыполнимая операция, которую в третьей модели решил алгоритм «вероятностного искажения». Он позволял для отсутствующих во время выравнивания позиций правильно генерировать эти необходимые вставки на языке перевода.
Модель 4 добавила в алгоритм учет перестановки слов. Так как часто два предложения могут иметь одну синтаксическую структуру, но отличаться порядком отдельных фраз. Как, например, предложения:
“He has lived in New York since last year”.
“Il habite depuis l’année dernière à New York”.
Имеющие ту же структуру, но отличающиеся расположением обстоятельства места, в частности, в английской фразе оно стоит в середине предложения, а во французском - в конце. Предыдущие модели оперировали в основном на уровне слов, и не справлялись с решением подобных задач. Модель 4 улучшила алгоритм «вероятностного искажения» Модели 3 и стала применять его для подобных «плавающих» блоков в предложениях.
Модель 5 не представляла сколько-либо серьезных изменений предыдущей модели, но добавила алгоритм разрешения конфликтов между словами за место в предложении. Эта модель была более точной математически, но требовала гораздо более сложных вычислительных подсчетов, а результаты оставались примерно такими же, или даже хуже, так как система требовала куда больше обучающих данных.
Однако отличительной чертой всех word-based моделей было то, что все они ничего не знали, как работать согласованием падежей, рода и омонимией, вследствие чего, были заменены на segment-based модели.
В основанном на сегменте моделе перевода цель состояла в том, чтобы уменьшить ограничения основанного на слове перевода, переводя целые последовательности слов, где длины предложений могут отличаться. Последовательности слов понимались в таком случае блоками или фраземами, (n-граммами) пересекающимися наборами из n-слов подряд, но, как правило, являлись не лингвистическими фраземами, а фраземами найденнымы, используя статистические методы корпусов. С 2006 года до 2016-го данную модель использовали Google Translate, Yandex переводчик, Bing Translate и др. Эти модели были достаточно просты и эффективны, и работали для многих языковых пар, но как и word-based модели не принимали в расчет общую структуру языка перевода, основываясь в процессе перевода лишь на небольших отрезках рядом стоящих слов, не учитывая межязыковых различий в построении структуры предложения (например, порядок слов подлежащее-сказуемое-дополнение в английском языке и подлежащее-допополнение-сказуемое в японском), что значительно уменьшало качество перевода.
Основанный на синтаксисе машинный перевод исходил из идеи перевести синтаксические единицы, а не отдельные слова или ряды слов (как в основанном на фразе машинном переводе), т.е. (частичные) ветви разбора предложений. Системы, основанные на синтаксисе, не были новы в машинном переводе, хотя их предыдущий аналог практически не использовался до появления сильных стохастических анализаторов в 1990-х. Примеры этого подхода включают основанный на данных парсера машинный перевод, и, позже, синхронные контекстно-свободные грамматики[7].
Иерархически основанный на фразе машинный перевод объединял в себе преимущества сразу двух подходов к машинному переводу - основанного на фразе, и основанного на синтаксисе. Эта модель использовала фразы (сегменты или группы слов) как единицы для перевода и синхронные контекстно-свободные грамматики в качестве правил (основанный на синтаксисе перевод). Дэвид Чанг[8] приводит Hiero как один из примеров данной модели.
Преимуществами статистических моделей машинного перевода являются достаточно высокое качество перевода при условии применения не слишком длинных фраз и достаточно тщательного проектирования и «обучения», возможность совершенствовать систему в процессе эксплуатации благодаря её «обучаемости», минимальные затраты на проектирование по сравнению со всеми остальными разновидностями систем машинного перевода.
К недостаткам относятся необходимость наличия больших параллельных корпусов текста и зависимость качества получаемого перевода от них, необходимость применения сложного математического аппарата, получение качественного перевода возможно только при условии попадания длины переводимой фразы в диапазон используемой n-граммной модели.
References
[1] 1. Bahl, L.R., Jelinet, F. & Mercer, R.L. (1983): "A maximum likelihood approach to continuous speech recognition", IEEE Trans. Pattern Anal.Machine Intel. 5(2), 179-190.
2. Brown, P. F., Cocke, J., Della-Pietra, S. A., et al. (1988). A statistical approach to language translation. In Proceedings of the International Conference on Computational Linguistics (COLING).
3.Brown, P. F., Cocke, J., Pietra, S. A. D., Pietra, V. J. D., Jelinek, F., Lafferty, J. D., Mercer, R. L., and Roossin, P. S. (1990). A statistical approach to machine translation. Comput. Linguist., 16(2):79–85.
4. Brown, P. F., Della-Pietra, S. A., Della-Pietra, V. J., and Mercer, R. L. (1993). The mathematics of statistical machine translation. Computational Linguistics, 19(2):263–313.
[2] Koehn, P. Statistical Machine Translation, Cambridge University Press, 2009, p.95.
[3] Brown, P., Cocke J., Della Pietra S.A., Della Pietra V. J., Jelinek F., Lafferty J. D., Mercer R. L., Roossin P.S. «A Statistical Approach to Machine Translation». In Readings in Machine Translation (S. Nirenburg, H. L. Somers, Y. Wilks, eds.), Cambridge, MA: MIT Press (2003), p. 355.
[4] Brown, P. F., Della-Pietra, S. A., Della-Pietra, V. J., and Mercer, R. L.The mathematics of statistical machine translation. Computational Linguistics, 1993.
[5] Poibeau, Thierry. Machine Translation. The MIT Press, 2017, p. 130.
[6] Poibeau, Thierry. Machine Translation. The MIT Press, 2017, p. 137.
[7] Williams P., Sennrich R., Post M., Koehn P. Syntax-based Statistical Machine Translation, 2016, p. 6.
[8] Chiang, David. A Hierarchical Phrase-Based Model for Statistical Machine Translation, 2005.
Machine Translation Omnibus
Машинный перевод на основе примеров
Машинный перевод на корпусах текстов
Машинный перевод на основе правил
Сколько всего видов машинного перевода?
От Декарта до Google Translate. Удивительная история машинного перевода